继续上次的xv6实验,从做完第一个实验后,到现在已经过去很久了6.S081-Lab: Xv6 and Unix utilities 操作系统实验分享。中途只做完了系统调用,也没有写上笔记。
这次学习xv6页表一章,从看书到看代码再到编写实验,花费了很多时间,遇到了很多坑,反反复复修改代码才得到正确的结果。
还是和以前一样,对操作系统有兴趣的千万不要错过这个实验。这次的实验会接触到很多内核知识,尤其是编写实验代码过程中,将页表理论知识化为实际的代码,别说有多舒服了。
分页可谓是操作系统中一个非常重要的思想,在操作系统中使用页表来和硬件一起实现内存虚拟化。对页表的理解当然不能仅仅只停留在理论上,
来看看xv6是如何实现它的。
下面的源码是依据 github 上的xv6源码进行解读的,导致我在读完源码后,再看6.S081的实验后有点迷茫。
另外,下面的实验是以 6.S081-2020 的课程进行的,不是 2021 的课程实验;这两年的实验不相同!!!
kernel/riscv.h 分页相关操作的定义
The flags and all other page hardware-related structures are defined in (kernel/riscv.h)
book-riscv-rev2.pdf-P33
在 riscv.h 文件中定义了页的一些标志和硬件相关的结构, 以下是该文件的部分源码
#define PGSIZE 4096
#define PGSHIFT 12
#define PGROUNDUP(sz) (((sz)+PGSIZE-1) & ~(PGSIZE-1))
#define PGROUNDDOWN(a) (((a)) & ~(PGSIZE-1))
#define PTE_V (1L << 0)
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4)
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
#define PTE2PA(pte) (((pte) >> 10) << 12)
#define PTE_FLAGS(pte) ((pte) & 0x3FF)
#define PXMASK 0x1FF
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))
typedef uint64 pte_t;
typedef uint64 *pagetable_t;从源码中能理解大部分的 define 语句是做什么的,比如页的大小、最大虚拟地址等,这里挑几个出来讲讲
结合书中的图3.2分析:
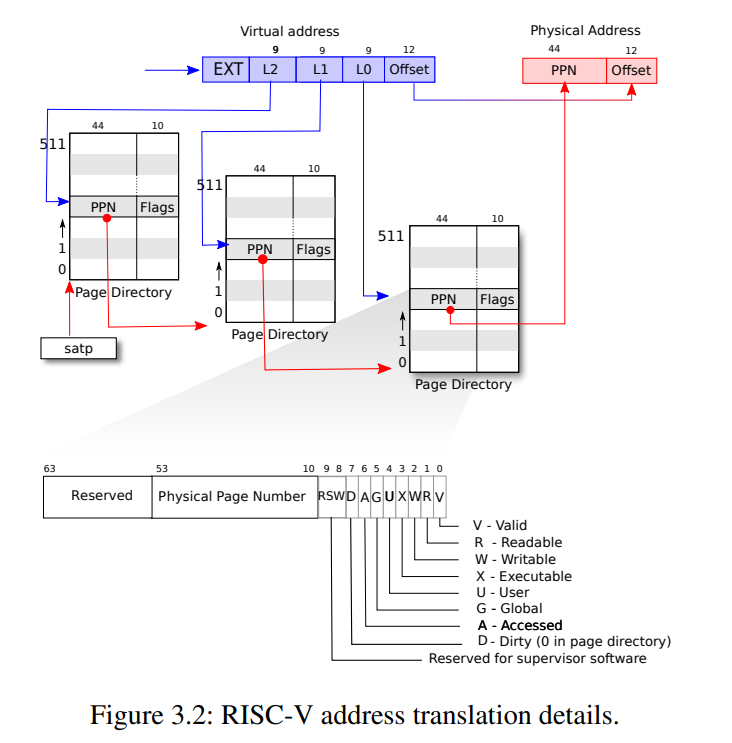
- PGROUNDUP:获取地址sz对应的物理页号(PPN),向上取整
- PGROUNDDOWN:同上,获取地址sz对应的物理页号(PPN),向下取整
- PTE_FLAGS:获取页表项对应的标志
- PXMASK:虚拟地址的低39位被 xv6 使用, 这39bit中的高27bit被用来索引页表项,xv6的页表是三级页表,
,这27bit被分为三次使用,每次使用9bit,因此PXMASK为0x1FF,PXSHIFT则是根据是第几级页表来计算移位数
xv6只使用了5个页标志,而不是图中RISC-V的8个标志。 至于 PA2PTE、PTE2PA,光看这个文件的话会难以理解,留到后续与其他文件一起解释。
类型 pagetable_t 将会在下面提到,只需记住,它是64位长的指针。
kernel/memlayout.h xv6内存布局
The file (kernel/memlayout.h) declares the constants for xv6’s kernel memory layout.
book-riscv-rev2.pdf-P34
这个文件定义了 xv6 的内存布局
#define UART0 0x10000000L
#define UART0_IRQ 10
#define VIRTIO0 0x10001000
#define VIRTIO0_IRQ 1
#define CLINT 0x2000000L
#define CLINT_MTIMECMP(hartid) (CLINT + 0x4000 + 8*(hartid))
#define CLINT_MTIME (CLINT + 0xBFF8)
#define PLIC 0x0c000000L
#define PLIC_PRIORITY (PLIC + 0x0)
#define PLIC_PENDING (PLIC + 0x1000)
#define PLIC_MENABLE(hart) (PLIC + 0x2000 + (hart)*0x100)
#define PLIC_SENABLE(hart) (PLIC + 0x2080 + (hart)*0x100)
#define PLIC_MPRIORITY(hart) (PLIC + 0x200000 + (hart)*0x2000)
#define PLIC_SPRIORITY(hart) (PLIC + 0x201000 + (hart)*0x2000)
#define PLIC_MCLAIM(hart) (PLIC + 0x200004 + (hart)*0x2000)
#define PLIC_SCLAIM(hart) (PLIC + 0x201004 + (hart)*0x2000)
#define KERNBASE 0x80000000L
#define PHYSTOP (KERNBASE + 128*1024*1024)
#define TRAMPOLINE (MAXVA - PGSIZE)
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
#define TRAPFRAME (TRAMPOLINE - PGSIZE)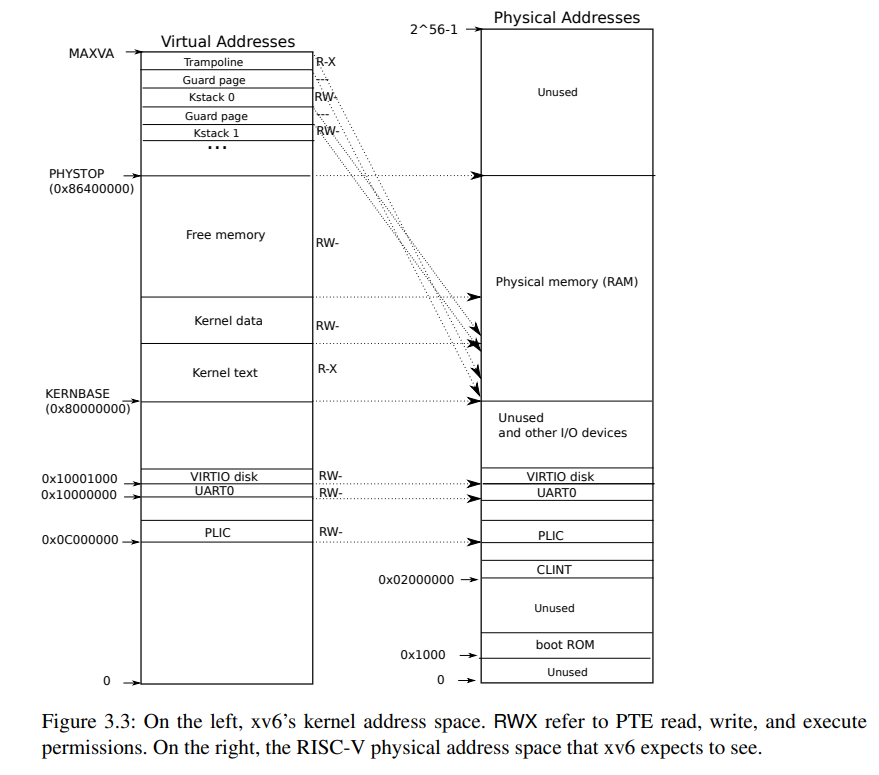
上面的代码和 book-riscv-rev2.pdf-P34 的图3.3所示的一致,正是xv6内核的地址空间布局,比如 KERNBASE 是 0x80000000 RAM 的起始地址,xv6内核使用的内存大小是 128M(KERNBASE ~ PHYSTOP 范围的地址空间)。另外,我们可以注意到,虚拟地址空间最高的那两页被分配给了 TRAMPOLINE 和 TRAPFRAME。
kernel/vm.c
Most of the xv6 code for manipulating address spaces and page tables resides in vm.c
book-riscv-rev2.pdf-P35
xv6绝大部分用于处理地址空间和页表的代码都在 kernel/vm.c 文件中,由于源码过长,不容易快速理解,现在按照书P36的内容来分析这里面的代码。在xv6启动的时候, kernel/main.c 在启用分页功能前,先调用了kvminit函数创建内核页表。
以下是kernel/main.c的main函数代码:
void
main()
{
if(cpuid() == 0){
consoleinit();
printfinit();
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit();
kvminit();
kvminithart();
procinit();
trapinit();
trapinithart();
plicinit();
plicinithart();
binit();
iinit();
fileinit();
virtio_disk_init();
userinit();
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart();
trapinithart();
plicinithart();
}
scheduler();
}现在我们只关注对vm.c中的函数调用,即kvminit和kvminithart。
kvminit 初始化内核页表
void
kvminit(void)
{
kernel_pagetable = kvmmake();
}这个函数只是调用kvmmake获取返回值后赋值给 kernel_pagetable,kernel_pagetable声明如下:
pagetable_t kernel_pagetable;pagetable_t 类型的变量,正是上述的riscv.h中定义的64位长的指针,也就说明kvmmake的返回了内核页表的指针。
现在看看kvmmake函数是如何创建内核页表的。
kvmmake
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// map kernel stacks
proc_mapstacks(kpgtbl);
return kpgtbl;
}kvmmake首先调用kalloc分配一个物理页并用零值初始化。kvmmake然后调用kvmmap对该页表设置虚拟地址-物理地址映射,并设置该页的标志(valid、read、write等),使用到的常量大多是在memlayout.h中定义的;
由于此时还没有开启分页,因此是直接映射(direct mapping),也就是虚拟地址等于物理地址。kvmmake接着调用proc_mapstacks为每个进程分配一个内核栈和一个守护页(guard page)的内存。- 最后,返回内核页表的指针
kpgtbl。
现在将注意力集中在页表是如何创建的,内存分配在后面讨论,我们查看kvmmap函数是如何做的:
kvmmap
void
kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kpgtbl, va, sz, pa, perm) != 0)
panic("kvmmap");
}kvmmap 调用了mappages函数,继续看mappages函数
mappages
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if(size == 0)
panic("mappages: size");
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}mappages函数的逻辑如下:
- 根据虚拟地址的起始地址
va和空间大小size,使用riscv.h中的PAGEDOWN获取虚拟地址的页号范围[a,last] - 在for循环中,调用
walk获取页号a对应的页目录项(PTE)的地址,walk函数会在页目录项未分配时(即PTE_V是0的状况)
为页目录项分配一页,分配失败时,walk返回 0,walk的逻辑会在后面详细介绍 - 接着会判断该目录项
pte是否重复映射,如果重复映射,则panic - 接着会将标志填充至要映射的物理页地址
pa,并将其赋给pte,使目录项pte指向该物理页 - 更新虚拟页地址
a和物理页地址pa并开始新一轮循环。
walk函数是如何获取页表pagetable中的虚拟地址a对应的页表项地址pte呢?
walk
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}walk函数的逻辑如下:
- 如果虚拟地址
a超过最大虚拟地址MAXVA(上述riscv.h中定义的),则报错 - 进入
for循环,循环会进行两次,因为xv6使用的三级页表,要跨过前两级页表,返回第三级页表的页表项地址;在for循环中,利用预处理操作PX
获取虚拟地址va对应level的9bit大小页表项索引(索引区间[0,511]共512个页表项,因为页表pagetable的大小就是一页,
页表项大小为8个字节,即4096/8=512,而va中的27bit被分成三个9bit使用,9bit刚好可以索引512个页表项),根据页表项是否valid,判断是否需要为该页表项分配内存- 如果
pte所指向的页已分配,则将pagetable指向页表项pte指向的页 - 如果
pte所指向的页未分配(没有设置valid),则会根据alloc标志参数是否设置,调用kalloc分配一页内存并初始化它
- 如果
- 最终,
pagetable指向三级页表的地址,然后使用虚拟地址va索引对应的页表项,返回页表项地址。 - 如果页表项地址未成功分配,则返回 0
kvmmap经及其使用的函数我们已经知道了,现在来看kvmmake中调用的最后一个函数proc_mapstacks
proc_mapstacks(proc.c)
void
proc_mapstacks(pagetable_t kpgtbl) {
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
kvmmap(kpgtbl, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
}
}proc_mapstacks调用kalloc分配一个物理页va用于存放内核栈,然后使用KSTACK生成的虚拟地址va,在内核页表上建立映射。
预处理操作KSTACK定义如下:
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)可见内核栈都是在TRAMPOLINE下面,相邻的内核栈相距2个物理页(1页用于内核栈,一页防止栈溢出覆盖数据),且分配顺序是自上而下(因为栈是向下增长的)。
结合proc_mapstacks中的p-proc不难看出,这是为每个进程划分的一块内核栈,互相独立。
对应于书中的xv6内核地址空间布局图。注意,所有进程的内核栈映射都在内核页表!!!
book-riscv-rev2.pdf#P34
- 由于是在初始化内核页表,因此索引到的页表项
pte大多情况下都是需要kalloc分配内存页 - 上述这些操作发生时,还没有开启分页功能,因此是虚拟地址-物理地址的直接映射(direct mapping),
walk将页表项指向的页的物理地址当成虚拟地址使用
引用原文的一段描述:
A page table is stored in physical memory as a three-level tree. The root of the tree is a 4096-byte
page-table page that contains 512 PTEs, which contain the physical addresses for page-table pages
in the next level of the tree. Each of those pages contains 512 PTEs for the final level in the tree.
The paging hardware uses the top 9 bits of the 27 bits to select a PTE in the root page-table page,
the middle 9 bits to select a PTE in a page-table page in the next level of the tree, and the bottom
9 bits to select the final PTE.book-riscv-rev2.pdf#32
现在,kvmminit初始化了内核页表,kernel_pagetable指向了内核根页表(root page-table),main.c接着接着调用
kvminithart函数启用分页并刷新TLB。
kvminithart 启用分页
void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
}w_astp使用汇编指令,将内核页表的物理地址写入到寄存器satpsfence_vma使用RISC_V的汇编指令刷新CPU的TLB(由于读取页表映射需要进行读取内存,因此使用TLB缓存这些映射,利用局部性原理加快速度)
kvminithart函数执行之后,后续指令使用到的虚拟地址都会被映射为正确的物理地址
kernel/kalloc.c
上述在初始化内核页表时,都是使用kalloc函数分配内存,现在来看看xv6的内存管理机制:
xv6使用一个链表来记录哪些页是可用的, 俗称”空闲链表“,且每次分配或释放的空间都是大小为4KB的页。
内存管理使用到结构体run来存储可分配空间的地址,结构体run定义如下:
struct run {
struct run *next;
};结构体run形成一个空闲页的链表,链表freelist和该链表的自旋锁则封装在另一个结构体kmem中:
struct {
struct spinlock lock;
struct run *freelist;
} kmem;只有在获取到自旋锁时,,才能分配或释放内存,以确保线程安全。
freelist用于记录空闲内存页,那么存储这些记录的内存又从哪里来呢?
xv6将空闲链表节点存储在空闲内存页当中,空闲页page中可以存储这样一个指针p,指针p的地址就是空闲页page的地址,指针p的内容就是下一个空闲页的地址。
记住这一点,将更容易理解下面xv6的源代码。
kinit 初始化可用内存
回到xv6的启动过程,在main.c调用kvminit函数创建页表之前,先调用了kinit函数初始化可用内存。
kinit
void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}在kinit函数中,先初始化了空闲链表的自旋锁,在这里先不考虑自旋锁的创建细节;随后调用freerange释放end~PHYSTOP范围的物理内存。
freerange是如何释放该范围内的物理地址呢?
freerange
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}freerange函数使用riscv.h中预处理操作PGROUNDUP获取起始物理页地址,之后对该范围内的物理页依次调用kfee添加到空闲页。
现在看看kfee函数对物理页做了什么操作:
kfree
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}kfee先对传入的物理地址pa进行合法性判断,如地址是否按4KB对齐,地址是否在正确范围内;随后对该物理地址的内容进行垃圾填充(对已经释放的物理地址的指针引用会更快失败)。
然后就是kree的重要操作了:对pa强转为run结构体的指针,这样pa指向的地址就是run结构体所在的地址(要释放的物理页上存储了run结构体),获取自旋锁后将该结构体加入到空闲链表freelist中。
结构体run的地址就是空闲物理页的地址,结构体run指针的内容就是下一个空闲页的物理地址。
综上,xv6在启动时,将空闲的物理页地址都记录在空闲链表freelist中;释放内存的逻辑已经清晰了,现在看看分配内存kalloc
kalloc 分配内存
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE);
return (void*)r;
}kalloc也是先获取空闲链表的自旋锁,然后取得空闲链表的第一个物理页地址,如果该地址非空,则更新空闲链表并进行垃圾填充,最后将该地址返回。
可以注意到的是,kfree和kalloc操作的都是物理内存地址。
关于 Lab: system calls
这里实验中需要编写一个获取可用内存大小的辅助函数,通过上面源码的学习,我们可以很轻松的编写代码。
下面是我在添加的实现:
函数原型(defs.h)
int free_mem_size(void);函数定义(kalloc.c)
uint64 free_mem_size(void)
{
struct run *beg;
uint64 ret;
acquire(&kmem.lock);
beg = kmem.freelist;
uint64 cnt = 0;
while (beg) {
beg = beg->next;
++cnt;
}
ret = cnt << 12;
release(&kmem.lock);
return ret;
}系统调用 sbrk
系统调用sbrk用于给进程增长或减少内存,sbrk通过growproc(proc.c)来实现这个功能,growproc又根据传入的参数值正负来决定是
调用uvmalloc(增加内存)还是调用uvmdealloc(减少内存)。下面使用到的页表均是对应进程的页表。
unvmalloc(vm.c)
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
oldsz = PGROUNDUP(oldsz);
for(a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0) {
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}unmalloc还是调用kalloc分配一个物理页(设置所有的标志位),随后调用mappages在页表pagetable上建立对应的映射。如果分配物理页失败或建立映射失败,
都会释放已经分配的物理页,并调用uvmdealloc将进程的内存大小由当前内存大小a设置为增长前的oldsz。
有一个问题需要思考:
获取进程原来的内存大小oldsz使用的是PGROUNDUP而不是PGROUNDDOWN,为什么呢?
因为内存分配是以4KB为单位的,进程内存大小如果是oldsz, 实际上进程的内存是包含oldsz所在页的。例如oldsz为1025,进程的内存大小正是PGROUNDUP得到的4096,使用PGROUNDDOWN是不正确的。
uvmdealloc(vm.c)
uint64
uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
if(newsz >= oldsz)
return oldsz;
if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){
int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE;
uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1);
}
return newsz;
}同uvmalloc,uvmdealloc也是使用PGROUNDUP获取实际的用户内存大小,并调用uvmunmap来清除内存映射。
uvmunmap定义如下:
uvmunmap
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
*pte = 0;
}
}uvmunmap调用walk从用户页表上找到对应的页表项并清除该映射。
另外,根据do_free标志参数来决定是否释放该物理页;uvmunmap是选择释放该物理页。
系统调用 exec
Exec is the system call that creates the user part of an address space. It initializes the user part
of an address space from a file stored in the file system
book-riscv-rev2.pdf#39
学习Linux的过程中,大都会接触到这个系统调用。简而言之,exec的作用就是将当前执行的程序替换成指定的程序。假如程序main.c调用exec,传入的参数是wc,运行main.c
那么现象就是:main.c好像没有执行(调用exec前的语句都执行了),wc执行了。exec系统调用肯定是在运行时做了很多事情。
现在来看看xv6中的exec系统调用是如何实现的 。
exec.c
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "riscv.h"
#include "spinlock.h"
#include "proc.h"
#include "defs.h"
#include "elf.h"
static int loadseg(pde_t *pgdir, uint64 addr, struct inode *ip, uint offset, uint sz);
int
exec(char *path, char **argv) {
char *s, *last;
int i, off;
uint64 argc, sz = 0, sp, ustack[MAXARG], stackbase;
struct elfhdr elf;
struct inode *ip;
struct proghdr ph;
pagetable_t pagetable = 0, oldpagetable;
struct proc *p = myproc();
begin_op();
if ((ip = namei(path)) == 0) {
end_op();
return -1;
}
ilock(ip);
// Check ELF header
if (readi(ip, 0, (uint64) &elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if (elf.magic != ELF_MAGIC)
goto bad;
if ((pagetable = proc_pagetable(p)) == 0)
goto bad;
// Load program into memory.
for (i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph)) {
if (readi(ip, 0, (uint64) &ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if (ph.type != ELF_PROG_LOAD)
continue;
if (ph.memsz < ph.filesz)
goto bad;
if (ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
sz = sz1;
if ((ph.vaddr % PGSIZE) != 0)
goto bad;
if (loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlockput(ip);
end_op();
ip = 0;
p = myproc();
uint64 oldsz = p->sz;
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, sz + 2 * PGSIZE)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz - 2 * PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
// Push argument strings, prepare rest of stack in ustack.
for (argc = 0; argv[argc]; argc++) {
if (argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc + 1) * sizeof(uint64);
sp -= sp % 16;
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, (char *) ustack, (argc + 1) * sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->trapframe->a1 = sp;
// Save program name for debugging.
for (last = s = path; *s; s++)
if (*s == '/')
last = s + 1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
return argc; // this ends up in a0, the first argument to main(argc, argv)
bad:
if (pagetable)
proc_freepagetable(pagetable, sz);
if (ip) {
iunlockput(ip);
end_op();
}
return -1;
}
// Load a program segment into pagetable at virtual address va.
// va must be page-aligned
// and the pages from va to va+sz must already be mapped.
// Returns 0 on success, -1 on failure.
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz) {
uint i, n;
uint64 pa;
for (i = 0; i < sz; i += PGSIZE) {
pa = walkaddr(pagetable, va + i);
if (pa == 0)
panic("loadseg: address should exist");
if (sz - i < PGSIZE)
n = sz - i;
else
n = PGSIZE;
if (readi(ip, 0, (uint64) pa, offset + i, n) != n)
return -1;
}
return 0;
}
exec是系统调用,操作系统中有一个概念:陷阱。用户进程进行系统调用时,会陷入操作系统,执行模式会提升至特权模式。因此exec是在特权模式下执行的。
由于exec代码比较长,忽略变量声明和begin_op()、end_op()日志相关操作,下面一步步来分析。
第一步:读取给定path获取文件inode
if ((ip = namei(path)) == 0) {
end_op();
return -1;
}第二步:读取并检查文件头 ELF Header
在文件头加入幻数(magic)来区分文件类型是一种很常用的手段,Java的字节码文件也是如此。xv6的应用程序使用ELF格式,因此这里调用readi从文件中读取内容到elf中。
一个ELF格式的文件由一个ELF header和一系列程序段头(struct proghdr)组成。每个proghdr描述了必须加载到内存中的应用程序部分;xv6程序只有一个程序段头。
if (readi(ip, 0, (uint64) &elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if (elf.magic != ELF_MAGIC)
goto bad;第三步:为进程分配一个新页表
if ((pagetable = proc_pagetable(p)) == 0)
goto bad;第四步:读取并将程序加载到内存
依次调用readi读取程序段头到ph中,并进行一系列的检查,并为每个ph调用uvmalloc分配相应的内存,并调用loadseg将程序加载到内存中。
loadseg调用walkaddr通过页表pagetable获取虚拟地址va+i对应的物理地址pa,并调用readi读取文件内容到pa,这样就完成了加载操作。
for (i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph)) {
if (readi(ip, 0, (uint64) &ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if (ph.type != ELF_PROG_LOAD)
continue;
if (ph.memsz < ph.filesz)
goto bad;
if (ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
sz = sz1;
if ((ph.vaddr % PGSIZE) != 0)
goto bad;
if (loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz) {
uint i, n;
uint64 pa;
for (i = 0; i < sz; i += PGSIZE) {
pa = walkaddr(pagetable, va + i);
if (pa == 0)
panic("loadseg: address should exist");
if (sz - i < PGSIZE)
n = sz - i;
else
n = PGSIZE;
if (readi(ip, 0, (uint64) pa, offset + i, n) != n)
return -1;
}
return 0;
} 第五步:为栈分配内存并初始化
调用uvmalloc增长2页内存,并将sp指向栈地址,保护页(guard page)地址为stackbase。
sz = PGROUNDUP(sz);
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, sz + 2 * PGSIZE)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz - 2 * PGSIZE);
sp = sz;
stackbase = sp - PGSIZE第六步:将传入的参数值数组argv复制到栈中
遍历传入的参数argv,减少sp的值(栈向下增长),并调用copyout(内核到用户空间)将参数值复制到栈上,同时使用ustack数组记录每一个参数值的指针。
for (argc = 0; argv[argc]; argc++) {
if (argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;第七步:将参数值指针ustack复制到栈中
减小栈指针的值,为copyout操作准备空间,调用copyout将参数值指针数组ustack和NULL(0)指针复制到栈中
sp -= (argc + 1) * sizeof(uint64);
sp -= sp % 16;
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, (char *) ustack, (argc + 1) * sizeof(uint64)) < 0)
goto bad;第八步:为后续程序准备第二个参数
sp现在是参数值指针的起始地址,对应于程序的第二个参数argv,存放在寄存器a1(第一个参数argc在寄存器a0)
p->trapframe->a1 = sp;第九步:修改进程对应状态并释放旧页表
修改进程对应的名称、页表、内存大小、保存的PC、栈指针等,然后调用proc_freepagetable释放进程的旧页表。
在快要成功时才进行释放页表,也算是一个小细节。
for (last = s = path; *s; s++)
if (*s == '/')
last = s + 1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);第十步:结束
后续程序的第一个参数argc通过返回值返回,刚好在寄存器a0,因此没有在上面像a1那样直接修改参数值。
return argc; // this ends up in a0, the first argument to main(argc, argv)- 此时内存中的内容完全是给定文件的内容了,
PC的内容也指定为main所在地址。此时从系统调用返回,操作系统会恢复进程的执行,将保存在
trapframe中的内容逐一加载(restore)到CPU,CPU将从该程序的main执行,且该程序将会使用argc和argv。这样,exec就达到了它的目的。 - 发生错误时,要记得关闭资源。xv6在这里也是采用了经典的错误处理流程,即
goto。
Lab: page tables
解读完上面的源码后,现在开始进行实验。实验过程中会修改一些源码文件,我会使用粗体标记源文件的名称及其修改的函数,进行展示的源码将不会用粗体标记。
Print a page table (easy)
To help you learn about RISC-V page tables, and perhaps to aid future debugging, your first task is to write a function that prints the contents of a page table.
Define a function called vmprint(). It should take a pagetable_t argument, and print that pagetable in the format described below. Insert if(p->pid==1) vmprint(p->pagetable) in exec.c just before the return argc, to print the first process's page table. You receive full credit for this assignment if you pass the pte printout test of make grade.
Now when you start xv6 it should print output like this, describing the page table of the first process at the point when it has just finished exec()ing init:page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000The first line displays the argument to vmprint. After that there is a line for each PTE, including PTEs that refer to page-table pages deeper in the tree. Each PTE line is indented by a number of " .." that indicates its depth in the tree. Each PTE line shows the PTE index in its page-table page, the pte bits, and the physical address extracted from the PTE. Don't print PTEs that are not valid. In the above example, the top-level page-table page has mappings for entries 0 and 255. The next level down for entry 0 has only index 0 mapped, and the bottom-level for that index 0 has entries 0, 1, and 2 mapped.
Your code might emit different physical addresses than those shown above. The number of entries and the virtual addresses should be the same.Some hints:
- You can put vmprint() in kernel/vm.c.
- Use the macros at the end of the file kernel/riscv.h.
- The function freewalk may be inspirational.
- Define the prototype for vmprint in kernel/defs.h so that you can call it from exec.c.
- Use %p in your printf calls to print out full 64-bit hex PTEs and addresses as shown in the example.
第一个实验在vm.c中定义函数vmprint();vmprint接受一个页表指针参数并以指定格式打印该页表建立的映射内容。
编写本代码前,需要看过riscv.h和vm.c的部分源码,了解页表的构成以及如何使用riscv.h中定义的PTE2PA获取页表项对应的页物理地址。
实验步骤
在vm.c中添加函数如下
void
vmprint(pagetable_t pagetable)
{
if (0 == pagetable) {
printf("vmprint: invalid pagetable!\n");
return;
}
printf("page table %p\n", pagetable);
// 三级迭代比递归更加清晰
pte_t pte;
// 512 PTES per page
for (int i = 0; i < 512; ++i) {
pte = pagetable[i];
if (pte & PTE_V) {
pagetable_t child_pgtbl = (pagetable_t)PTE2PA(pte);
printf("..%d: pte %p pa %p\n", i, pte, child_pgtbl);
pte_t child_pte;
for (int j = 0; j < 512; ++j) {
child_pte = child_pgtbl[j];
if (child_pte & PTE_V) {
pagetable_t cchild_pgtbl = (pagetable_t)PTE2PA(child_pte);
printf(".. ..%d: pte %p pa %p\n", j, child_pte, cchild_pgtbl);
pte_t cchild_pte;
for (int k = 0; k < 512; ++k) {
cchild_pte = cchild_pgtbl[k];
if (cchild_pte & PTE_V) {
printf(".. .. ..%d: pte %p pa %p\n", k, cchild_pte, PTE2PA(cchild_pte));
}
}
}
}
}
}
}因为xv6使用的是三级页表,每级页表中的页表项打印格式互不相同,因此采用三层迭代实现,效率更高也更直观。
在defs.h中添加函数原型如下
// vm.c
// ...
void vmprint(pagetable_t);在exec.c的函数exec返回前,添加下列代码,来打印第一个进程的页表内容:
// exec
// ...
if (1 == p->pid)
vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
// ...第一个实验较为简单,不对细节进行过多描述。
细节
- 通过
PTE2PA获取下一级页表指针时,需要进行类型转换 - 注意每一级的打印格式
A kernel page table per process (hard)
Xv6 has a single kernel page table that's used whenever it executes in the kernel. The kernel page table is a direct mapping to physical addresses, so that kernel virtual address x maps to physical address x. Xv6 also has a separate page table for each process's user address space, containing only mappings for that process's user memory, starting at virtual address zero. Because the kernel page table doesn't contain these mappings, user addresses are not valid in the kernel. Thus, when the kernel needs to use a user pointer passed in a system call (e.g., the buffer pointer passed to write()), the kernel must first translate the pointer to a physical address. The goal of this section and the next is to allow the kernel to directly dereference user pointers.
Your first job is to modify the kernel so that every process uses its own copy of the kernel page table when executing in the kernel. Modify struct proc to maintain a kernel page table for each process, and modify the scheduler to switch kernel page tables when switching processes. For this step, each per-process kernel page table should be identical to the existing global kernel page table. You pass this part of the lab if usertests runs correctly.
Read the book chapter and code mentioned at the start of this assignment; it will be easier to modify the virtual memory code correctly with an understanding of how it works. Bugs in page table setup can cause traps due to missing mappings, can cause loads and stores to affect unexpected pages of physical memory, and can cause execution of instructions from incorrect pages of memory.Some hints:
- Add a field to struct proc for the process's kernel page table.
- A reasonable way to produce a kernel page table for a new process is to implement a modified version of kvminit that makes a new page table instead of modifying kernel_pagetable. You'll want to call this function from allocproc.
- Make sure that each process's kernel page table has a mapping for that process's kernel stack. In unmodified xv6, all the kernel stacks are set up in procinit. You will need to move some or all of this functionality to allocproc.
- Modify scheduler() to load the process's kernel page table into the core's satp register (see kvminithart for inspiration). Don't forget to call sfence_vma() after calling w_satp().
- scheduler() should use kernel_pagetable when no process is running.
- Free a process's kernel page table in freeproc.
- You'll need a way to free a page table without also freeing the leaf physical memory pages.
- vmprint may come in handy to debug page tables.
- It's OK to modify xv6 functions or add new functions; you'll probably need to do this in at least kernel/vm.c and kernel/proc.c. (But, don't modify kernel/vmcopyin.c, kernel/stats.c, user/usertests.c, and user/stats.c.)
- A missing page table mapping will likely cause the kernel to encounter a page fault. It will print an error that includes sepc=0x00000000XXXXXXXX. You can find out where the fault occurred by searching for XXXXXXXX in kernel/kernel.asm.
xv6有一个单独的内核页表,当在内核执行时,就会用到它。内核页表是直接映射的(direct mapping),即虚拟地址x就是物理地址x。
xv6还为每个进程的用户地址空间提供了一个单独的页表,仅包含该进程用户内存的映射,从虚拟地址零开始。
内核页表当然不会包含用户内存映射,因此用户地址在内核页表是非法的。
因此,当内核需要使用在系统调用中传递的用户指针(例如,传递给write()的缓冲区指针)时,内核必须首先将指针转换为物理地址,因为在内核中使用的虚拟地址就相当于物理地址。
现在需要为每个进程添加一个内核页表,使每个进程在内核执行时,使用的是进程自己的内核页表副本。
实验步骤
1. 为进程添加内核页表字段
要为每个进程添加一个内核页表,当然得在进程的定义中去修改。
文件proc.h中的结构体proc定义了进程相关的状态,这里面就有用户页表字段,我们仿照它的格式添加一个内核页表字段。
proc.h#proc
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
pagetable_t kernel_pagetable;// Kernel page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};现在进程可以存放一个内核页表了,下一步就是为进程创建页表。
2. 添加创建内核页表函数
综合之前内容以及提示,可以知道vm.c中的kvminit函数创建了内核页表。
kvminit()
{
kernel_pagetable = (pagetable_t) kalloc();
memset(kernel_pagetable, 0, PGSIZE);
// uart registers
kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
kvmmap(CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}现在仿照这个函数创建一个内核页表并返回给进程。由于kvmmap使用的页表是固定的,即vm.c中定义的全局变量。
void
kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kernel_pagetable, va, sz, pa, perm) != 0)
panic("kvmmap");
}我们需要创建一个类似的函数,将页表作为参数,以便为进程的内核页表添加映射。
vm.c#uvmmap
// add a mapping to the process's kernel page table.
void
uvmmap(pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(pagetable, va, sz, pa, perm) != 0)
panic("uvmmap");
}现在,编写函数创建内核页表并返回,而不是赋值给全局变量。函数名选用了proc_kpgtblcreate,可以选用其他名称。
该函数大体和kvmmint一致,只是由kvmmap变为上面编写的uvmmap为页表添加映射。
vm.c#proc_kpgtblcreate
// create kenel page table for process
pagetable_t
proc_kpgtblcreate(void)
{
pagetable_t kpgtbl = kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
uvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
uvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
uvmmap(kpgtbl, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
uvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
uvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
uvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
uvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
return kpgtbl;
}为了能够在其他文件中调用这个函数,在文件defs.h中添加如下函数声明:
defs.h
// vm.c
// ...
void uvmmap(pagetable_t, uint64, uint64, uint64, int);
pagetable_t proc_kpgtblcreate(void);为了能够在其他文件中调用这个函数,在文件defs.h中添加如下函数声明:
defs.h
// vm.c
// ...
void uvmmap(pagetable_t, uint64, uint64, uint64, int);
pagetable_t proc_kpgtblcreate(void);3. 修改进程创建逻辑
上面已经添加了创建内核页表的函数,现在需要在进程创建时为其创建内核页表。根据提示,找到文件proc.c中的函数allocproc
static struct proc *
allocproc(void) {
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
// Allocate a trapframe page.
if ((p->trapframe = (struct trapframe *) kalloc()) == 0) {
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if (p->pagetable == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64) forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}这个函数中为进程创建并赋予了用户页表,我们在其中仿照该逻辑,插入内核页表创建。这个实验的提示还告诉我们需要为内核页表添加内核栈(kenel stack)映射,
内核栈映射的代码可以从文件proc.c中的函数procinit中找到。
void
procinit(void) {
struct proc *p;
initlock(&pid_lock, "nextpid");
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va;
}
kvminithart();
}这个函数为每个进程分配了栈内存,并在全局内核页表(kvmmap)上建立映射。现在需要将这个建立映射的逻辑转移到进程的内核页表上。
修改如下:
proc.c#allocproc
static struct proc *
allocproc(void) {
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
// Allocate a trapframe page.
if ((p->trapframe = (struct trapframe *) kalloc()) == 0) {
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if (p->pagetable == 0) {
goto fail;
}
// A kernel page table for process
p->kernel_pagetable = proc_kpgtblcreate();
if (p->kernel_pagetable == 0) {
goto fail;
}
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
char *pa = (char *) kalloc();
if (pa == 0)
panic("allocproc: kalloc");
uint64 sva = KSTACK((int) (p - proc));
uvmmap(p->kernel_pagetable, sva, (uint64) pa, PGSIZE, PTE_R | PTE_W);
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64) forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
fail:
freeproc(p);
release(&p->lock);
return 0;
}- 仿照
pagetable的创建过程,创建kernel_pagetable - 使用
goto完成统一错误处理 - 将函数
procinit建立内核栈映射的部分代码转移到allocproc - 调用
uvmmap而不是kvmmap建立映射
proc.c#procinit
void
procinit(void) {
struct proc *p;
initlock(&pid_lock, "nextpid");
for (p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
uint64 va = KSTACK((int) (p - proc));
p->kstack = va;
}
kvminithart();
}- 保留对进程设置内核栈地址的语句
4. 添加释放内核页表函数
如果注意的话,可以发现在上面的allocproc错误处理流程中,调用了函数freeproc释放进程。
实验的提示也告诉我们需要修改freeproc以释放内核页表。
static void
freeproc(struct proc *p) {
if (p->trapframe)
kfree((void *) p->trapframe);
p->trapframe = 0;
if (p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}释放用户页表用到了proc_freepagetable,仿照它,编写函数proc_freekpgtbl。
proc.c#proc_freekpgtbl
void
proc_freekpgtbl(pagetable_t kpgtbl, uint64 kstack) {
// free the kernel stack page
uvmunmap(kpgtbl, kstack, 1, 1);
uvmkpg_freewalk(kpgtbl);
}- 内核栈是在分配进程的时候创建的,因此释放进程时,要释放对应的物理内存;这里仿照了
proc_freepagetable函数。 - 内核页表上的其他映射只是建立映射,没有分配内存,因此,不应该释放其对应的物理内存。
当然,在这里可以对proc_kpgtblcreate中建立的PLIC、KERNBASE、etext等映射都调用uvmunmap来清除映射,但是很容易出错。
这里仿照proc_freepagetable调用函数链上的freewalk编写了函数uvmkpg_freewalk。
在vm.c中添加函数uvmkpg_freewalk的定义:
vm.c#uvmkpg_freewalk
// Recursively free kenel page-table pages without also freeing the leaf physical memory pages
void
uvmkpg_freewalk(pagetable_t kpgtbl)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = kpgtbl[i];
if (pte & PTE_V) {
// this PTE points to a lower-level page table.
if ((pte & (PTE_R | PTE_W | PTE_X)) == 0) {
uvmkpg_freewalk((pagetable_t) PTE2PA(pte));
}
// clear the mapping
kpgtbl[i] = 0;
}
}
kfree((void*)kpgtbl);实验提示中也有说到:
You'll need a way to free a page table without also freeing the leaf physical memory pages.
uvmkpg_freewalk是仿照函数freewalk编写的
// Recursively free page-table pages.
// All leaf mappings must already have been removed.
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child);
pagetable[i] = 0;
} else if(pte & PTE_V){
panic("freewalk: leaf");
}
}
kfree((void*)pagetable);
}和freewalk不同的是,uvmkpg_freewalk也会处理leaf pte(即三级页表中最低级页表中的页表项),而不是报错。
uvmkpg_freewalk通过扫描页表中所有页表项,如果该页表项是有效的(设置了PTE_V标志)
- 如果该页表项还包含
PTE_R、PTE_W、PTE_X中任意一个标志,则说明该页表项是一个leaf,不再进行深层递归;将页表项释放后再释放页表。 - 否则说明还有下一级页表,进行递归。
5. 修改调度程序
按照提示,我们需要修改文件proc.c中的函数scheduler()。在进程切换的时候,将进程的内核页表地址写入寄存器satp并刷新TLB缓存。
在进程运行完毕后,调用函数kvminithart,使用全局的内核页表。
proc.c#scheduler
void
scheduler(void) {
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for (;;) {
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
int found = 0;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
// use process's kernel page table instead
w_satp(MAKE_SATP(p->kernel_pagetable));
sfence_vma();
swtch(&c->context, &p->context);
// use global kernel page table
kvminithart();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
found = 1;
}
release(&p->lock);
}
#if !defined (LAB_FS)
if (found == 0) {
intr_on();
asm volatile("wfi");
}
#else
;
#endif
}
}6. 修改内核虚拟地址转换函数
这个点是一个坑点,实验的提示并没有提到这个点。因此做完上面的修改后,直接运行,会出现异常。
除非追踪kernel_pagetable被使用到的地方。
// translate a kernel virtual address to
// a physical address. only needed for
// addresses on the stack.
// assumes va is page aligned.
uint64
kvmpa(uint64 va)
{
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(kernel_pagetable, va, 0);
if(pte == 0)
panic("kvmpa");
if((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa+off;
}从注释来看,这个函数是用于将栈上的虚拟地址转换为物理地址,而这里用到的还是全局的内核页表。
因此,会很自然想到,要修改它使用进程的内核页表。
为了在文件vm.c中使用进程结构,还需要引入两个文件:
vm.c#kvmpa
// #include...
#include "spinlock.h"
#include "proc.h"
//...
uint64
kvmpa(uint64 va)
{
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(myproc()->kernel_pagetable, va, 0);
if(pte == 0)
panic("kvmpa");
if((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa+off;
}7. 添加函数声明
为了使上面的函数能够被调用,在文件defs.h添加的函数声明如下(包括第一次实验)
defs.h
// proc.c
// ...
void proc_freekpgtbl(pagetable_t, uint64);
// ...
// vm.c
// ...
void vmprint(pagetable_t);
void uvmmap(pagetable_t, uint64, uint64, uint64, int);
pagetable_t proc_kpgtblcreate(void);
void uvmkpg_freewalk(pagetable_t);Simplify copyin/copyinstr (hard)
The kernel's copyin function reads memory pointed to by user pointers. It does this by translating them to physical addresses, which the kernel can directly dereference. It performs this translation by walking the process page-table in software. Your job in this part of the lab is to add user mappings to each process's kernel page table (created in the previous section) that allow copyin (and the related string function copyinstr) to directly dereference user pointers.
Replace the body of copyin in kernel/vm.c with a call to copyin_new (defined in kernel/vmcopyin.c); do the same for copyinstr and copyinstr_new. Add mappings for user addresses to each process's kernel page table so that copyin_new and copyinstr_new work. You pass this assignment if usertests runs correctly and all the make grade tests pass.
This scheme relies on the user virtual address range not overlapping the range of virtual addresses that the kernel uses for its own instructions and data. Xv6 uses virtual addresses that start at zero for user address spaces, and luckily the kernel's memory starts at higher addresses. However, this scheme does limit the maximum size of a user process to be less than the kernel's lowest virtual address. After the kernel has booted, that address is 0xC000000 in xv6, the address of the PLIC registers; see kvminit() in kernel/vm.c, kernel/memlayout.h, and Figure 3-4 in the text. You'll need to modify xv6 to prevent user processes from growing larger than the PLIC address.Some hints:
- Replace copyin() with a call to copyin_new first, and make it work, before moving on to copyinstr.
- At each point where the kernel changes a process's user mappings, change the process's kernel page table in the same way. Such points include fork(), exec(), and sbrk().
- Don't forget that to include the first process's user page table in its kernel page table in userinit.
- What permissions do the PTEs for user addresses need in a process's kernel page table? (A page with PTE_U set cannot be accessed in kernel mode.)
- Don't forget about the above-mentioned PLIC limit.
Linux uses a technique similar to what you have implemented. Until a few years ago many kernels used the same per-process page table in both user and kernel space, with mappings for both user and kernel addresses, to avoid having to switch page tables when switching between user and kernel space. However, that setup allowed side-channel attacks such as Meltdown and Spectre.
内核通过遍历进程的页表将用户指针转换为物理地址,内核就可以对其直接进行解引用。
在这个实验中,需要将用户映射(user mappings)添加到进程的内核页表上(上个实验中创建的),以便函数copyin和copyinstr可以直接对用户指针解引用。
实验步骤
1. 修改函数copyin
按照实验提示,第一步应当修改文件vm.c中的函数copyin的函数体,将其变为对文件vmcopyin.c中的函数copyin_new的调用。
但是文件defs.h中并没有声明copyin_new的原型,需要在该文件中添加原型才可以成功链接。为了方便起见,所有添加的函数原型将在最后一步列出。
vm.c#copyin
int
copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len)
{
return copyin_new(pagetable, dst, srcva, len);
// uint64 n, va0, pa0;
//
// while(len > 0){
// va0 = PGROUNDDOWN(srcva);
// pa0 = walkaddr(pagetable, va0);
// if(pa0 == 0)
// return -1;
// n = PGSIZE - (srcva - va0);
// if(n > len)
// n = len;
// memmove(dst, (void *)(pa0 + (srcva - va0)), n);
//
// len -= n;
// dst += n;
// srcva = va0 + PGSIZE;
// }
// return 0;
}2. 创建复制用户页表映射函数
实验提示我们需要在内核修改进程的用户映射时,以同样的方式修改进程的内核页表。
内核修改用户映射的地方有fork()、exec()、userinit()和sbrk()。仔细观察这些函数,可以确定函数的原型。
至于如何复制映射,可以仿照fork复制用户页表所调用的函数uvmcopy。
编写函数uvmmap_copy如下:
vm.c#uvmmap_copy
// Given a process page table, copy its mappings into a kernel page table
// Only copies the page table.
// returns 0 on success, -1 on failure.
// unmap any mappings on failure.
int
uvmmap_copy(pagetable_t upgt, pagetable_t kpgt, uint64 beg, uint64 end)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = beg; i < end; i += PGSIZE){
if((pte = walk(upgt, i, 0)) == 0)
panic("uvmmap_copy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmmap_copy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte) & (~PTE_U);
if(mappages(kpgt, i, PGSIZE, pa, flags) != 0){
goto err;
}
}
return 0;
err:
uvmunmap(kpgt, 0, i / PGSIZE, 0);
return -1;
}相较于uvmcopy,uvmmap_copy不会分配实际的物理页,只会创建映射。可以理解为深拷贝和浅拷贝。
细节
- 实验提示我们思考内核页表中的页表项的标志。用户映射会带有
PTE_U,内核模式下是无法访问这些页表项的。因此在复制映射时,
需要去除页表项中的PTE_U标志,这是通过PTE_FLAGS(*pte) & (~PTE_U)实现的。
3. 修改函数fork
现在有了复制用户映射的函数,现在就需要在这些地方调用这个函数,使内核页表包含用户映射。
函数fork定义如下:
int
fork(void) {
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if ((np = allocproc()) == 0) {
return -1;
}
// Copy user memory from parent to child.
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0) {
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
np->parent = p;
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
// Cause fork to return 0 in the child.
np->trapframe->a0 = 0;
// increment reference counts on open file descriptors.
for (i = 0; i < NOFILE; i++)
if (p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE;
release(&np->lock);
return pid;
}fork调用了uvmcopy将父进程的页表拷贝到子进程的页表中。我们仿照它对内核页表进行拷贝。
proc.c#fork
int
fork(void) {
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if ((np = allocproc()) == 0) {
return -1;
}
// Copy user memory from parent to child.
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0) {
goto fail;
}
np->sz = p->sz;
// Copy user mappings to kernel page table
if (uvmmap_copy(np->pagetable, np->kernel_pagetable, 0, np->sz) < 0) {
goto fail;
}
np->parent = p;
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
// Cause fork to return 0 in the child.
np->trapframe->a0 = 0;
// increment reference counts on open file descriptors.
for (i = 0; i < NOFILE; i++)
if (p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE;
release(&np->lock);
return pid;
fail:
freeproc(np);
release(&np->lock);
return -1;
}这里的修改还包括统一错误处理流程fail。
4. 修改函数userinit
userinit在main.c中被调用,用于创建第一个用户进程。我们仿照fork,对其进行修改即可。
proc.c#userinit
void
userinit(void) {
struct proc *p;
p = allocproc();
initproc = p;
// allocate one user page and copy init's instructions
// and data into it.
uvminit(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
// Copy user mappings to kernel page table
if (uvmmap_copy(p->pagetable, p->kernel_pagetable, 0, PGSIZE) < 0)
panic("userinit: uvmmap_copy");
// prepare for the very first "return" from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointer
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
p->state = RUNNABLE;
release(&p->lock);
}5. 修改函数growproc
实验提示我们,系统调用sbrk也会修改用户映射,我们在文件sysproc.c中找到sbrk的定义如下:
uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
addr = myproc()->sz;
if(growproc(n) < 0)
return -1;
return addr;
}系统调用实际是通过函数growproc来实现的,我们再找到文件proc.c中的函数growproc。
int
growproc(int n) {
uint sz;
struct proc *p = myproc();
sz = p->sz;
if(n > 0) {
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
} else if(n < 0) {
sz = uvmdealloc(p->pagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}这个函数通过调用uvmalloc(增大内存)和uvmdealloc(减少内存)。 在上面有分析过这两个函数,还不了解它们如何实现的,可以去看看。
仿照uvmalloc和uvmdealloc的实现,我们分别调用uvmmap_copy和uvmunmap。
proc.c#growproc
int
growproc(int n) {
uint sz;
struct proc *p = myproc();
sz = p->sz;
uint beg;
uint end;
if (n > 0) {
beg = sz;
// prevent user processes from growing larger than the PLIC address.
if (sz + n > PLIC || (sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
end = sz;
if (end >= beg) {
uvmmap_copy(p->pagetable, p->kernel_pagetable, PGROUNDUP(beg), end);
}
} else if (n < 0) {
beg = sz;
sz = uvmdealloc(p->pagetable, sz, sz + n);
end = sz;
if (end < beg && PGROUNDUP(end) < PGROUNDUP(beg)) {
int npages = (PGROUNDUP(beg) - PGROUNDUP(end)) / PGSIZE;
uvmunmap(p->kernel_pagetable, PGROUNDUP(end), npages, 0);
}
}
p->sz = sz;
return 0;
}细节
- 为了使复制的用户映射一致,代码逻辑和
uvmalloc、uvmdealloc相同。 uvmalloc是增长内存,因此实验要求的增长内存不能超过PLIC可以在这里实现。
6. 修改函数exec
现在修改exec函数,这个函数在前文也有分析。在exec做好所有准备后,在其赋值前,进行页表内容的复制。
exec.c#exec
int
exec(char *path, char **argv)
{
char *s, *last;
int i, off;
uint64 argc, sz = 0, sp, ustack[MAXARG+1], stackbase;
struct elfhdr elf;
struct inode *ip;
struct proghdr ph;
pagetable_t pagetable = 0, oldpagetable;
struct proc *p = myproc();
begin_op();
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
// Check ELF header
if(readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if(elf.magic != ELF_MAGIC)
goto bad;
if((pagetable = proc_pagetable(p)) == 0)
goto bad;
// Load program into memory.
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
sz = sz1;
if(ph.vaddr % PGSIZE != 0)
goto bad;
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlockput(ip);
end_op();
ip = 0;
p = myproc();
uint64 oldsz = p->sz;
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc+1) * sizeof(uint64);
sp -= sp % 16;
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, (char *)ustack, (argc+1)*sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->trapframe->a1 = sp;
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(p->name, last, sizeof(p->name));
// clear old user mappings before copy
uvmunmap(p->kernel_pagetable, 0, PGROUNDUP(oldsz) / PGSIZE, 0);
if (uvmmap_copy(pagetable, p->kernel_pagetable, 0, sz) < 0) {
// 内核页表已经被清除了, 此时复制新的用户映射出错了, 只能panic
panic("exec: uvmmap_copy");
}
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
if (1 == p->pid)
vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
bad:
if(pagetable)
proc_freepagetable(pagetable, sz);
if(ip){
iunlockput(ip);
end_op();
}
return -1;
}这里需要注意的是,在复制页表之前,需要对旧页表的内容进行清除。当然,也可以释放旧页表,然后创建一个新的页表,然后使用新页表复制,就和exec所做的一样。
至此,所有内核修改用户映射的地方,都会同样地修改进程的内核页表。
7. 修改函数创建内核页表函数
这里是一个坑点,很长时间不知道为什么测试失败。实验只是告诉我们用户地址空间不要超过PLIC,却忽略了下面这张图。
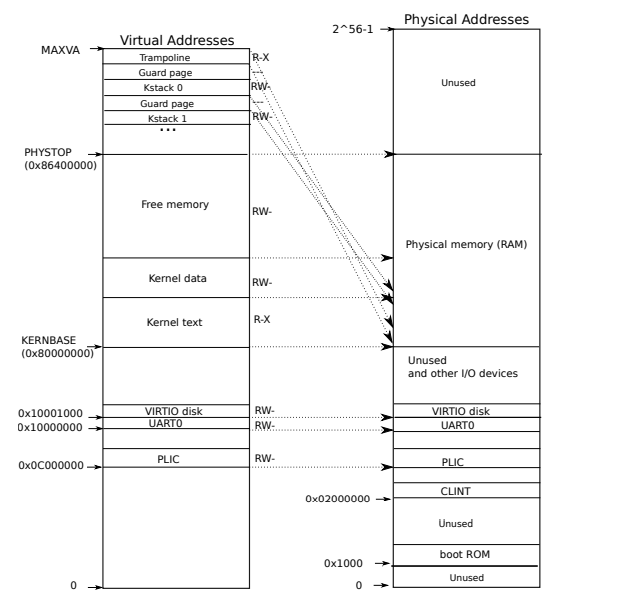
在为进程创建内核页表的时候,我们建立了CLINT映射(CLINT < PLIC)。用户地址空间是从虚拟地址0开始的,我们只限制其地址不能超过PLIC,
但是没有限制其不能超过CLINT。这个实验里,我们会在进程的内核页表上建立用户映射,那么就有可能出现重映射,即与虚拟地址CLINT重复。
实验要求进程的地址空间不能超过PLIC,因此,我们不能加上CLINT的限制,只能在内核页表创建时,不建立CLINT映射。
vm.c#proc_kpgtblcreate
pagetable_t
proc_kpgtblcreate(void)
{
pagetable_t kpgtbl = kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
uvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
uvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT,may cause remap
// uvmmap(kpgtbl, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
uvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
uvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
uvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
uvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
return kpgtbl;
}8. 添加函数原型
所有步骤均已完成。三个实验用到的函数原型在文件defs.h中的声明如下:
defs.h
// proc.c
// ...
// vm.c
// ...
void vmprint(pagetable_t);
void uvmmap(pagetable_t, uint64, uint64, uint64, int);
pagetable_t proc_kpgtblcreate(void);
void uvmkpg_freewalk(pagetable_t);
int uvmmap_copy(pagetable_t, pagetable_t, uint64, uint64);
void proc_freekpgtbl(pagetable_t, uint64);
// ...
// vmcopyin.c
int copyin_new(pagetable_t, char *, uint64, uint64);
int copyinstr_new(pagetable_t, char *, uint64, uint64);
// ...实验结果
完成所有实验后,编写问题答案answers-pgtbl.txt以及时间花费文件time.txt。
运行指令make grade,这个实验的测试时间会比较长,等待一会可以看到结果。
实验后的问题
- Explain the output of vmprint in terms of Fig 3-4 from the text. What does page 0 contain? What is in page 2? When running in user mode, could the process read/write the memory mapped by page 1?
这个问题是问一个进程的内存页包含了什么内容。
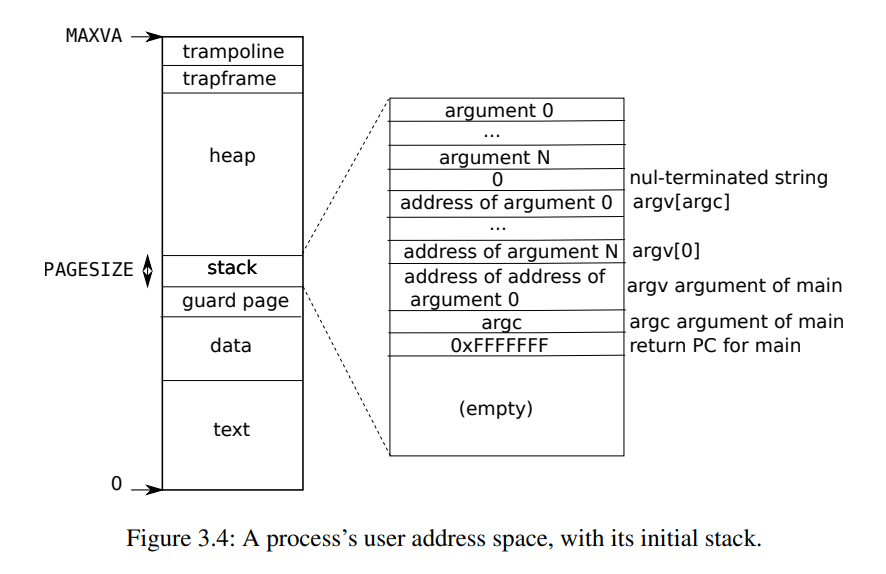
通过书中的图3.4可以知道,进程的虚拟地址以0开始,存放着代码和数据,然后是guard page和stack...。
在实验过程中,有接触过系统调用exec;exec正好是为进程创建了一个新的页表,可以从这里找到答案。
先看看exec的代码:
// Load program into memory.
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
sz = sz1;
if(ph.vaddr % PGSIZE != 0)
goto bad;
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}exec在创建新页表后,首先调用了uvmalloc为读取的程序段分配内存并在页表上设置映射;可以猜测:page0包含的是进程的代码段和数据段。
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;exec随后又分配了2页物理内存,一页用于用户栈,一页用于防止栈溢出覆盖其他数据。栈地址sp和保护页地址stackbase与图3.4所示相同:
栈位于高地址,保护页位于低地址,两者地址相差1页;可以猜测:guard page是page1,用户模式(user mode)下不可访问。stack是page2,即用户栈,包含的是进程在栈上保存的一些本地变量、参数等。
至此,问题1就弄清楚了。
- Explain why the third test srcva + len < srcva is necessary in copyin_new(): give values for srcva and len for which the first two test fail (i.e., they will not cause to return -1) but for which the third one is true (resulting in returning -1).
参数srcva 和 len 都是64位无符号整数,无符号整数加法发生溢出时,得到的结果是正数,但会比srcva和len都要小。
因此srcva + len < srcva是用来检测溢出的。比如 srcva = 4096, len = UINT64MAX - 4095的情况;srcva >= p->sz(false)、src + len >= p->sz(发生溢出,0 >= p->sz, false)、srcva + len < srcva(0 < p->sz, true)。可见,如果没有这个溢出判断,就会复制用户空间之外的内存,可能导致内核被破坏。
至此,问题2也弄清楚了。当然,想了解更多的溢出知识,推荐阅读CSAPP-深入理解计算机系统-第三版,在第二章-P61可以学习无符号加法的原理。
结语
前两个实验只是简单的窥探一下xv6内核,这次的实验则对页表有了一次深入的挖掘,尽管xv6的实现比较简单,如假定了内存的起始地址(实际上,内存的起始地址是不固定的)。通过编写实验代码、阅读xv6的源码,对内存虚拟化有了更深入的理解,是真正能够动手操作一番的。相较于只是阅读书籍并理解相关定义,还是动手操作的更令人激动。后面的实验就是操作系统的陷阱表了Lab: traps。
