

图的基本概念
在学习图之前,我们首先要了解图本身的意思。在汉字中,图是古代在生物毛皮或者绢帕上绘制的关于边境城市或者各种边界结构的资料,而在计算机中,当我们需要表示像社交网络一样的关系的时候,就需要用到图。它被广泛应用于网络路由、社交网络分析、图像处理等领域。
图的定义
图是由节点或者顶点和边组成的一种数据结构,用于描述物体之间的关系,是一种多对多的关系,图记为G = (V, E),其中V = {v1, v2,...,vn}代表图G顶点的集合,E = {(u,v)|u in V, v in V}代表边的集合。
注意⚠️:线性表可以是空表,树可以是空树,但图不可以是空图。图中不能一个顶点也没有,图的顶点集 V一定非空,但边集 E 可以为空,此时图中只有顶点而没有边。
图的基本术语
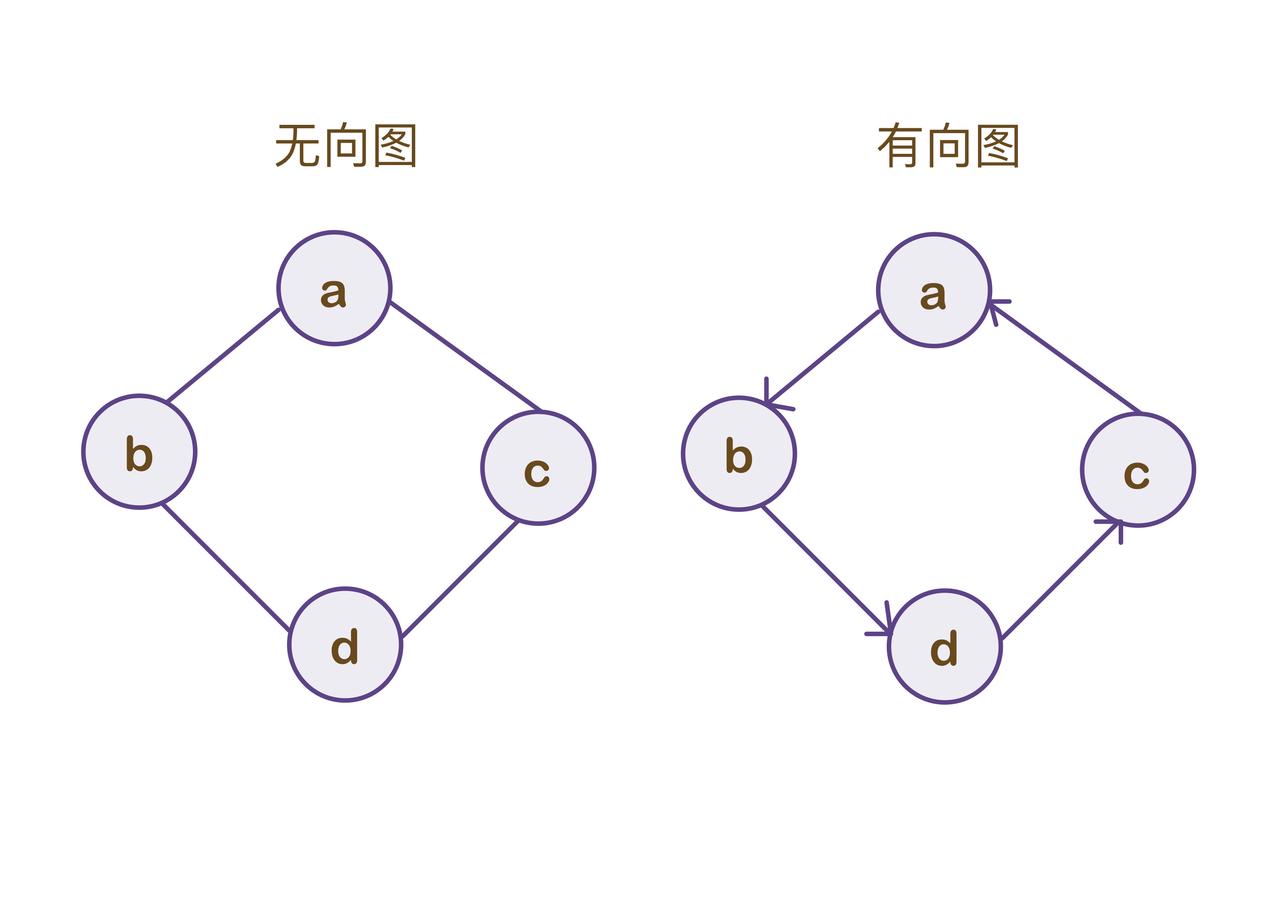
- 有向图:如果 E 是有向边的集合,则图 G 为有向图,每一条有向边被记作为〈v, w〉,这条边是由顶点 v 指向顶点 w 的边,也称为 v 临接到 w。
- 无向图:如果 E 是无向边的集合,则图 G 为无向图,每一条有向边被记作为(v, w),表明顶点 v 和顶点 w 有一条边,但是这条边没有方向,也称为 v 与 w 相互邻接。
- 完全图:对于含有 n 个顶点的无向图,当且仅当含有n(n-1)/2条边的无向图称为完全图,在完全图中任意两个顶点之间都存在边。对于含有 n 个顶点的有向图,有n(n-1)条边的有向图称为有向完全图,在有向完全图中任意两个顶点之问都存在方向相反的两条弧。
- 子图:类似子集,就是一个图拆分出来的多个子图。
- 连通、连通图和连通分量(无向图):在无向图中,若从顶点 v 到顶点 w 有路径存在,则称 v 和 w 是连通的。若图 G 中任意两个顶点都是连通的,则称这个图是连通图,否则为非连通图。无向图中的极大连通子图称为连通分量。
- 强连通图和强连通分量(有向图):在有向图中,如果有一对顶点 v 和 w,从 v 到 w 和从 w 到 v 之间都有路径则称这两个顶点是强连通的。若图中任何一对顶点都是强连通的,则称此图为强连通图。有向图中的极大强连通子图称为有向图的强连通分量。
- 顶点的度、入度和出度:

- 路径:对无向图来说,是顶点之间的边,有向图中的路径也是有向的,即有箭头指向。
- 生成树:对连通的图进行遍历,即走路径,过程中所经过的边和顶点的组合把它看成一棵树,就称为生成树
图的存储
在图论中,常用两种方式对图进行存储,分别为邻接矩阵存储法和邻接表表示法,根据不同的需求,可以在这两种方法中进行选择,下面分别对其进行介绍。
邻接矩阵存储法
所谓邻接矩阵,是指用一个二维的数组表示图中边的关系,而顶点的信息则可以使用另外的一维数组表示,下面为一个无向图的邻接矩阵表示法。

在边信息中,行和列的坐标为顶点信息数组下标,所以边的信息矩阵是一个大小的方阵。
1&\text{if } (v_i,v_j)或<v_i,v_j>是图中的一条边 \\
0 &\text{if } (v_i,v_j)或<v_i,v_j>不是图中的一条边
\end{cases}$$
在带权图中(这里以有向带权图为例),则邻接表对应的位置存储的应为边对应的权重信息。
{:width=700}
$$A[i][j] = \begin{cases}
w_{ij}&\text{if } (v_i,v_j)或<v_i,v_j>是图中的一条边 \\
0或∞ &\text{if } (v_i,v_j)或<v_i,v_j>不是图中的一条边
\end{cases}$$
图的邻接矩阵表示法数据结构定义如下:
```
// AdjacencyMatrixGraph 邻接矩阵存储图
public class AdjacencyMatrixGraph {
// numVertices 图中顶点的数量
private int numVertices;
// vex 图中顶点集合
private String[] vex
// adjacencyMatrix 图中边集
private int[][] adjacencyMatrix;
}
```
注意⚠️:在很多应用中,经常可以看到在定义图的数据结构时,并没有指定图中顶点集合,那是因为当顶点为信息为数字的时候,完全可以用边集合的下标去表示顶点信息;但是当顶点信息不是数字的时候,那么无法用边集合的下标表示,因此必须使用一个顶点数组去存储顶点的信息,在实际应用中,应当对这里进行注意。
图的邻接矩阵表示法特点(重点):
- 无向图的邻接矩阵一定是一个对称矩阵(并且唯一)。因此在存储时可以考虑矩阵的压缩,只存上三角或下三角矩阵即可。
- 对于无向图,邻接矩阵的第 i 行(或第 i 列)非零元素(或非 ∞ 元素)的个数正好是顶点 i 的度。
- 对于有向图,邻接矩阵的第 i 行非零元素(或非 ∞ 元素)的个数正好是顶点 i 的出度;第 j 列非零元素(或非 ∞ 元素)的个数正好是顶点 j 的入度 。
- 用邻接矩阵存储图,判断两个节点之间是否有边相连,只需要通过下标访问邻接矩阵即可,时间复杂度为O(1)。
- 当图中含有 n 个顶点时,邻接矩阵表示法空间复杂度为O(n^2),其空间复杂度与边的个数无关,仅与顶点个数有关,因此稠密图适合使用邻接矩阵的存储表示。
- 设图 G 的邻接矩阵为 A,A^n的元素 A^n[i][j] 表示由顶点 i 到顶点 j 的长度为 n 的路径的数目。结论性特点,有兴趣可参考离散数学进行证明。
\#\# 邻接表存储法
在上述邻接矩阵表示法中,可以看到其时间复杂度只和顶点的个数有关,但是当图为一个稀疏图时,会浪费大量的存储空间。为了弥补邻接矩阵的缺点,出现了邻接表表示法。所谓邻接表,是指为每个顶点建立一个单链表(当然数组也可以),将所有以该顶点为起点的边都存放在其单链表中,这个点单链表就称为这个节点的边表,边表的表头存储顶点信息,如下图所示。
{:width=480}
从上图中可以看出,邻接表表示法会包含两类节点类型,分别为顶点表中的节点类型,边表中的节点类型,两类节点类型如下图。(当然如果每个节点信息如果都是数字的话,也可以使用一种节点去表示两种节点信息,甚至可以使用一个二维 int 类型数组去表示顶点和边的信息,会在后面练习题中进行介绍。只要能表示出节点之间的关系即可)
{:width=480}
具体数据结构代码如下:
```
// ArcNode 边表节点类型
public class ArcNode {
// adjvex 邻接点在边表中的下标
private int adjvex;
// next 指向下一个节点的指针
private ArcNode next;
}
// Vnode 顶点表节点类型
public class Vnode {
// data 顶点信息
private int data;
// head 边表头指针,用于指向邻接表的第一个节点
private ArcNode head;
}
// ALGraph 邻接表表示法存储图
public class ALGraph {
// adjList 邻接表
private Vnode[] adjList;
}
```
图的邻接表表示法特点(重点):
- 在图的邻接表表示法中,边表是无序,因此邻接表表示法并不为一。在实例图中,边表中的每个节点按照从小到大进行排列,只是为了方便观察,但是在实际应用中往往邻接表中的单链表节点顺序并不全是从小到大进行排列的,取决于建立邻接表的算法和输入边的顺序,这点需要注意。
- 若图为无向图,则所需的存储空间为O(|V| + 2|E|);若图为有向图,则所需的存储空间为O(|V| + |E|)。前者的倍数 2 是由于无向图中,每条边在邻接表中出现了两次。
- 在邻接表中,给定一顶项点,能很容易地找出它的所有邻边,因为只需要读取它的邻接表。在邻接矩阵中,相同的操作则需要扫描一行,花费的时间为O(n)。但是,若要确定给定的两个顶点间是否存在边,则在邻接矩阵中可以立刻查到,而在邻接表中则需要在相应结点对应的边表进行便利。
- 在有向图的邻接表表示中,求一个给定顶点的出度只需计算其邻接表中的结点个数;但求其顶点的入度则需要遍历全部的邻接表。因此,也有人采用逆邻接表的存储方式来加速求解给定节点的入度。
\# 图的遍历(重点)
图的遍历是指从图中的某一顶点出发,按照某种搜索算法沿着图中的边对图中所有的顶点进行访问并且只访问一次。由于树是一种特殊的图,其便利方式和树有异曲同工之妙。图常见的遍历方式有两种:深度优先搜索(DFS)和广度优先搜索(BFS)。
我们可以回想一下,图相对于树来说,其最主要的不同之处有两点,图是一个多对多的模型,而树是一种一对多的模型;图中可能会存在环而树中不存在环。由于这两点不同,其实我们要解决的一个重要问题是,当便利到一个节点的时候,这个节点可能已经通过别的路径访问过了,或者是因为图中存在环的问题,导致同一个节点会被访问两次,而在树的遍历中却不用考虑这种问题。
\#\# 深度优先遍历(DFS)
图的深度优先搜索(Depth-Frist-Search,DFS)其实和二叉树的前序遍历很像,都是尽可能深的去进行搜索,我们可以完全参考二叉树树的前序列遍历,与其不同的地方仅仅在于二叉树只有两个分支,直接进行枚举即可,但是图中的一个节点会含有多个叉,其实我们只需要使用循环语句对边表或者邻接矩阵进行遍历即可;其次就是需要一个数组去记录被访问过的节点,如果节点被访问过了,那么直接跳过即可。
以邻接矩阵为例,具体实现代码如下
```
// AdjacencyMatrixGraph 邻接矩阵存储图
public class AdjacencyMatrixGraph {
// numVertices 图中顶点的数量
private int numVertices;
// vex 图中顶点集合
private String[] vex
// adjacencyMatrix 图中边集
private int[][] adjacencyMatrix;
// isVisit 用于记录被访问过的节点
private boolean[] isVisited;
// dfs 深度优先搜索
public void dfs(int node){
// 判断当前节点是否访问过,如果访问过直接返回
if(isVisited(node)){
return;
}
// 否则将当前节点设置为已经访问
isVisited[node] = true;
// 打印出当前节点信息
System.out.print(vex[node] + " ")
// 对其邻接矩阵进行深度优先遍历,其实和一个普通多叉树遍历很相似
for(int i = 0 ; i < vex.length; ++i){
// 如果两个节点之间有一条边,则对其进行递归
if (adjacencyMatrix[node][i] != 0){
dfs(i)
}
}
}
}
```
以邻接表为例,具体实现代码如下
```
// ArcNode 边表节点类型
public class ArcNode {
// adjvex 邻接点在边表中的下标
private int adjvex;
// next 指向下一个节点的指针
private ArcNode next;
}
// Vnode 顶点表节点类型
public class Vnode {
// data 顶点信息
private int data;
// head 边表头指针,用于指向邻接表的第一个节点
private ArcNode head;
}
// ALGraph 邻接表表示法存储图
public class ALGraph {
// adjList 邻接表
private Vnode[] adjList;
// isVisit 用于记录被访问过的节点
private boolean[] isVisited;
// dfs 深度优先搜索
public void dfs(int node){
// 判断当前节点是否访问过,如果访问过直接返回
if(isVisited(node)){
return;
}
// 否则将当前节点设置为已经访问
isVisited[node] = true;
// 打印出当前节点信息
System.out.print(adjList[node].data + " ")
// 找到邻接表的第一节点的位置
ArcNode cur = new ArcNode();
cur = adjList[node].head;
// 对其邻接表进行遍历即可
while(cur != null){
dfs(cur.adjvex)
cur = cur.next
}
}
}
```
算法性能分析(重点):
时间复杂度:遍历图的过程实质上是对每个顶点查找其邻接点的过程,其耗费的时间取决于所用的存储结构。以邻接矩阵表示时,需要遍历整个邻接矩阵,所以总的时间复杂度为O(|V|^2);以邻接表表示时,需要便利整个顶点表和边表,因此时间复杂度为O(|V|+|E|)。
空间复杂度:DFS 算法是一个递归算法,需要使用一个栈,其空间复杂度为O(|V|)。
广度优先生成树和生成森林:
根据深度优先搜索会产生一棵深度优先生成树。当然,这是有条件的,即对连通图调用 DFS 才能产生深度优先生成树,否则产生的将是深度优先生成森林,如下图所示。基于邻接表存储的深度优先生成树或森林可是不唯一的。
{:width=480}
\#\# 广度优先遍历(BFS)
图的广度优先搜索(Breadth-Frist-Search,DFS)其实和二叉树的层序遍历很像,一层一层的对其进行遍历,我们可以完全参考二叉树树的层序列遍历,其中需要使用到队列,我们同样需要解决和图的深度搜索所存在两个问题即可。
以邻接矩阵为例,具体实现代码如下
```
// AdjacencyMatrixGraph 邻接矩阵存储图
public class AdjacencyMatrixGraph {
// numVertices 图中顶点的数量
private int numVertices;
// vex 图中顶点集合
private String[] vex
// adjacencyMatrix 图中边集
private int[][] adjacencyMatrix;
// bfs 广度度优先搜索
public void bfs(int node){
boolean[] isVisited = new boolean[vex.length];
Queue<Integer> queue = new LinkedList<>();
// 将初始节点加入到队列中
isVisited[startVertex] = true;
queue.offer(startVertex);
// 打印出当前节点信息
System.out.print(vex[node] + " ")
// 当队列不空时,进行遍历,其实和树的层序遍历相同
while (!queue.isEmpty()) {
// 队头元素出队
int curNode = queue.poll();
System.out.print(vex[curNode] + " ");
// 对其邻接矩阵进行遍历
for (int i = 0; i < vex.length; ++i) {
// 如果存在一条边,并且没有被访问过,则入队
if (adjacencyMatrix[curNode][i] != 0 && !isVisited[i]) {
isVisited[i] = true;
queue.offer(i);
}
}
}
}
}
```
以邻接表为例,具体实现代码如下
```
// ArcNode 边表节点类型
public class ArcNode {
// adjvex 邻接点在边表中的下标
private int adjvex;
// next 指向下一个节点的指针
private ArcNode next;
}
// Vnode 顶点表节点类型
public class Vnode {
// data 顶点信息
private int data;
// head 边表头指针,用于指向邻接表的第一个节点
private ArcNode head;
}
// ALGraph 邻接表表示法存储图
public class ALGraph {
// adjList 邻接表
private Vnode[] adjList;
// bfs 广度度优先搜索
public void bfs(int node){
boolean[] isVisited = new boolean[vex.length];
Queue<Integer> queue = new LinkedList<>();
// 将初始节点加入到队列中
isVisited[startVertex] = true;
queue.offer(startVertex);
// 打印出当前节点信息
System.out.print(vex[node] + " ")
ArcNode cur = new ArcNode();
// 当队列不空时,进行遍历,其实和树的层序遍历相同
while (!queue.isEmpty()) {
// 队头元素出队
int curNode = queue.poll();
System.out.print(vex[curNode] + " ");
// 找到邻接表的第一节点的位置
cur = adjList[curNode].head;
// 对其邻接表进行遍历
while (cur != null) {
// 如果存在一条边,并且没有被访问过,则入队
if (!isVisited[cur.adjvex]) {
isVisited[cur.adjvex] = true;
queue.offer(cur.adjvex);
}
cur = cur.next
}
}
}
}
```
算法性能分析(重点):
时间复杂度:采用邻接表存储方式时,每个顶点均需搜索一次(或入队一次),故时间复杂度为O(|V|),在搜索任一顶点的邻接点时,每条边至少访问一次,故时间复杂度为O(|E|),算法总的时间复杂度为O(|V|+|E|);采用邻接矩性在储方式时,需要遍历整个邻接矩阵,所以总的时间复杂度为O(|V|^2)。
空间复杂度:无论是邻接表还是邻接矩阵的存储方式,BFS 都需要借助一个辅助队列,每个顶点均需入队一次,在最坏的情况下,空间复杂度为O(|V|)。
广度优先生成树:
在广度遍历的过程中,可以得到一棵遍历树,称为广度优先生成树,如下图所示。需要注意的是,一给定图的邻接矩阵存储表示是唯一的,故其广度优先生成树也是唯一的,但由于邻接表存储表示不唯一,故其广度优先生成树也是不唯一的。
{:width=480}
\# 图的应用
\#\# 图的连通性
图的连通性,是图论中的一个重要讨论话题。
对于一个无向图而言,如果仅仅一次 BFS 和 DFS 能够将整个图中所有节点都遍历一次,那么这个无向图是一个连通的无向图,否则为非连通的。如果需要 n 次 DFS 或 BFS才能将图遍历一次,那么这么这个无向图中就含有 n 个连通分量;对于有向图来说,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有顶点。
因此可以在进行 DFS 或 BFS 中添加 for 循环,再选取初始点,继续进行遍历,以防止一次无法遍历因的所有顶点。对于无向图而言,调用 DFS 或 BFS 的次数等于该图的连通分量数:而对于有向图则不是这样,因为一个连通的有向图分为强连通的和非强连通的,它的连通子图也分为强连通分量和非强连通分量,非强连通分量一次调用 BFS 或 DFS 无法访问到该连通分量的所有顶点。
\#\# 最小生成树
在图的遍历中曾经提到了生成树问题,同时生成树问题也是图论中的经典问题。根据不同遍历方式会产生多种生成树,其中生成树中所有边的权重和最小的树被称为最小生成树。最小生成树kennel不唯一,但是其权重之和是相同的,同时对于一个含有 n 个顶点的图,其生成树有且仅有 n-1 条边。
在最小生成树算法中,常用的的算法有两种,分别为 Prim 算法和 Kruskal 算法。在最小生成树中,需要解决两个问题,第一个问题是如何选择出所需要的 n-1 条边,第二问题是选择出来的边不能使得树中出现环。
\#\#\# 1. Prim算法
Prim 算法的思想是给定一个起始顶点,加入树 T 之后选择一个与当前 T 集合中顶点距离最近的顶点加入 T 以此类推直到所有顶点都都加入到 T 中,也就是进行了 n-1 次循环,其中 n 代表图中顶点数量。可以看出 Prim 算法是一个以顶点贪心为策略的算法。
下图表示以 0 为初始节点的 Prime 算法过程:
{:width=480}
下面给出算法具体实现代码,结果会打印出一个一个的数对,并且用“:”隔开,冒号前代表当前轮选择的节点,整个数对表示每一轮选择的边。
```
// 以邻接矩阵表示法表示,并且是一个无向图,并且以 0 为起始节点
import java.util.Arrays;
// Graph 图
public class Graph {
// vertices 节点个数
private int vertices;
// adjacencyMatrix 邻接矩阵
private int[][] adjacencyMatrix;
public Graph(int v) {
vertices = v;
adjacencyMatrix = new int[v][v];
}
// addEdge 初始化图的边
public void addEdge(int source, int destination, int weight) {
adjacencyMatrix[source][destination] = weight;
adjacencyMatrix[destination][source] = weight;
}
public void primMST() {
// lowcost 数组用于表示每个顶点到 T 的最短距离,初始值为无穷大
// lowcost[i] 表示第 i 个顶点到 T 的最短距离
int[] lowcost = new int[vertices];
Arrays.fill(lowcost, Integer.MAX_VALUE);
// vIn 数组用来表示已经在 T 中的节点
// vIn[i] 表示顶点 i 是否在 T 中,由于起始节点是 0 所以 vIn[0] = true
boolean[] vIn = new boolean[vertices];
Arrays.fill(vIn, false);
vIn[0] = true;
// 由于初始节点是 0 号节点, 所以初始时 T 中只包含 0 号节点,
// 那么其余所有节点到 T 的最短距离就是到节点 0 的距离
for(int i = 1 ; i < vertices; ++i){
if (adjacencyMatrix[i][0] > 0){
lowcost[i] = adjacencyMatrix[i][0];
}
}
// parent 用于记录当前节点的逻辑父节点
// parent[i] 表示第 i 个节点通过 parent[i]节点与 T 相连接时,距离最短
// 初始化 parent[0],其没有父节点,因为其为起始节点
int[] parent = new int[vertices];
parent[0] = -1;
// 进行 vertices - 1 次循环,选择出 vertices - 1 条边
for(int j = 0 ; j < vertices - 1; ++j) {
// 首先找到距离 T 距离最小的节点和边对应的边
int minIdx = -1;
int minVal = Integer.MAX_VALUE;
for (int i = 0; i < vertices; i++) {
// 需要判断当前节点是否在 T 中,并且要找到距离最小的那条边
// 避免生成环
if (!vIn[i] && lowcost[i] < minVal) {
minIdx = i;
minVal = lowcost[i];
}
}
// 此节点需要加入到 T 中
vIn[minIdx] = true;
System.out.println(minIdx + ":" + parent[minIdx]);
// 找到与 T 连接的边
for(int i = 0 ; i < vertices; ++i){
// 如果当前节点没有被选择,并且当前节点和当前距离 T 最近的节点有一条边,并且距离小于当前最小距离
// parent数组,与lowcost 数组进行更新
if(!vIn[i] && adjacencyMatrix[minIdx][i] != 0 && adjacencyMatrix[minIdx][i] < lowcost[i]){
parent[i] = minIdx;
lowcost[i] = adjacencyMatrix[minIdx][i];
}
}
}
}
}
public class Main {
public static void main(String[] args) {
int V = 6; // 图的顶点数
Graph graph = new Graph(V);
graph.addEdge(0, 1, 6);
graph.addEdge(0, 2, 1);
graph.addEdge(0, 3, 5);
graph.addEdge(1, 2, 5);
graph.addEdge(1, 4, 3);
graph.addEdge(2, 4, 6);
graph.addEdge(2, 5, 4);
graph.addEdge(2, 3, 5);
graph.addEdge(3, 5, 2);
graph.addEdge(4, 5, 6);
graph.primMST();
}
}
```
\#\#\# 2. Kruskal
Kruskal 算法与 Prim 算法思想略有不同,并且不需要起始顶点,Kruskal 算法完全是对每一轮选择的边进行贪心,而不在关心顶点的信息,每一轮去选择一条权重最小并且不会使生成树出现环的边,通过 n-1 次这样的选边循环,完成最小生成树的创建。
下图为 Kruskal 算法创建最小生成树的过程
{:width=480}
在 Kruskal 算法中,每当选择一条权重最小的边时,必须要考虑的一件事是选择的这条边不能使得生成树中出现环,那么可以使用并查集的方式去进行判断。如上图,当我们在进行最后一轮选择边的时候,其中存在(1,2)、(0,3)、(2,3)三条边的权重都是 5,但如果选择(0,3)这条边的话,如果通过并查集去查询 0 的根节点和 3 的根节点,就会发现它们两个的根结点是一样的,如果此时将(0,3)这条边加入到 T 中那么必然会生成环,但是选择(1,2)这条边就不会出现这样的情况。
具体实现代码如下,结果会打印出一个一个的数对,并且用“:”隔开,冒号前代表当前轮选择的节点,整个数对表示每一轮选择的边。
```
// 无向图
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
// Graph 图
public class Graph {
// vertices 节点个数
private int vertices;
// edges 边列表
private List<Edge> edges;
public Graph(int v) {
vertices = v;
edges = new ArrayList<>();
}
// addEdge 向图中添加一条边
public void addEdge(int source, int destination, int weight) {
Edge edge = new Edge(source, destination, weight);
edges.add(edge);
}
public void kruskalMST() {
// 根据边的权重进行排序
Collections.sort(edges, Comparator.comparingInt(e -> e.weight));
// 初始化并查集
DisjointSet disjointSet = new DisjointSet(vertices);
List<Edge> minimumSpanningTree = new ArrayList<>();
// 遍历排序后的边
for (Edge edge : edges) {
int sourceParent = disjointSet.find(edge.source);
int destinationParent = disjointSet.find(edge.destination);
// 如果边的两个顶点不属于同一个集合,则将边添加到最小生成树中
if (sourceParent != destinationParent) {
minimumSpanningTree.add(edge);
disjointSet.union(sourceParent, destinationParent);
}
}
// 5. 输出最小生成树的边和权重
for (Edge edge : minimumSpanningTree) {
System.out.println(edge.source + ":" + edge.destination);
}
}
// Edge 边数据结构
private class Edge {
// source 起始节点
int source;
// destination 结束节点
int destination;
// weight 边的权重
int weight;
public Edge(int src, int dest, int w) {
source = src;
destination = dest;
weight = w;
}
}
}
// DisjointSet 并查集
class DisjointSet {
private int[] parent;
private int[] rank;
public DisjointSet(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 0;
}
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
// 为了平衡并查集树的高度
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
public class Main {
public static void main(String[] args) {
int V = 6; // 图的顶点数
Graph graph = new Graph(V);
graph.addEdge(0, 1, 6);
graph.addEdge(0, 2, 1);
graph.addEdge(0, 3, 5);
graph.addEdge(1, 2, 5);
graph.addEdge(1, 4, 3);
graph.addEdge(2, 4, 6);
graph.addEdge(2, 5, 4);
graph.addEdge(2, 3, 5);
graph.addEdge(3, 5, 2);
graph.addEdge(4, 5, 6);
graph.kruskalMST();
}
}
```
\#\#\# 3. 两种算法对比
Prim 算法的时间复杂度为O(|V|^2),不依赖于边的数量 ,因此 Prim 适用于求解边稠密的图的最小生成树。
Kruskal 算法的时间复杂度为 O(|E|log|E|),不依赖于顶点的数量,因此 Kruskal 算法适合于稀疏图。
\#\# 最短路径
在图论中点到点的路径往往不止一条,将从一个顶点到另一个顶点的带权路径相加就到得到了两点之间的路径长度,最短路径就是路径长度最小的那条。在最短路径问题中,通常有两种问题,第一种问题是在图中,一个节点到其余所有节点的最短路径是多少;另一个问题是在图中各个顶点之间的路径是多少。求解这两个问题,我们通常使用 Dijkstra 算法和 Floyd 算法,下面分别进行介绍。
\#\#\# 1. Dijkstra(单源最短路径)
在单源最短路径问题中,需要给定一个起始节点,找到起始节点到其余所有节点的最短路径。其算法主要思想是每次在备选节点中选择一个距离起始节点最近的节点,并且如果以这个节点为中转节点能够缩减其他未被选择的节点到起始节点的距离,则对它们到起始节点的距离进行更新,重复上述过程,直到所有节点都被选择。
算法流程示意图如下
{:width=700}
{:width=720}
下面给出 Dijkstra 算法求解代码。
// 以邻接矩阵表示法表示,并且是一个有向图
```
import java.util.Arrays;
// Graph 图
public class Graph {
// inf 定义最大值
private static final int INF = 10000007;
// vertices 节点个数
private int vertices;
// adjacencyMatrix 邻接矩阵
private int[][] edge;
public Graph(int v) {
vertices = v;
edge = new int[v][v];
// 初始化邻接矩阵
for(int i = 0; i < edge.length; ++i){
Arrays.fill(edge[i], INF);
}
}
// addEdge 初始化图的边
public void addEdge(int source, int destination, int weight) {
edge[source][destination] = weight;
}
public int[] Dijkstra(int start) {
// visit 记录被访问过的节点
boolean[] visit = new boolean[vertices];
// distance 源点可达的节点当前最短距离
// distance[i] 表示第 i 个节点当前距离源点的最短距离
// 初始时设置位置 int 最大值表示不可达
int[] distance = new int[vertices];
Arrays.fill(distance, INF);
// 初始化源点,源点距离自己的距离是 0
distance[start] = 0;
// 开始进行循环
for (int k = 0; k < vertices; ++k){
// 找到距离源点距离最近的节点,t 代表当前轮距离源点最近的节点
int t = -1;
for (int i = 0; i < vertices ; ++i){
// 如果当前节点没有被访问并且(t还有被赋值或者找到一个更近的节点)
// 那么就更新 t 的值
if (!visit[i] && (t == -1 || distance[i] < distance[t])){
t = i;
}
}
// 将当前节点设置为被访问过
visit[t] = true;
// 使用当前轮次选择出来的节点,如果能够通过当前轮次选择出来的节点当作中转节点将距离缩短,
// 那么就更新最短距离 distance 数据
for (int i = 0; i < vertices ; ++i){
// !!!!!这一步将是重点
distance[i] = Math.min(distance[i], distance[t] + edge[t][i]);
}
}
return distance;
}
}
public class Main {
public static void main(String[] args) {
int V = 5; // 图的顶点数
Graph graph = new Graph(V);
graph.addEdge(0, 1, 10);
graph.addEdge(0, 4, 5);
graph.addEdge(1, 2, 1);
graph.addEdge(1, 4, 2);
graph.addEdge(2, 3, 4);
graph.addEdge(3, 0, 4);
graph.addEdge(3, 2, 6);
graph.addEdge(4, 1, 3);
graph.addEdge(4, 2, 9);
graph.addEdge(4, 3, 2);
int[] distance = graph.Dijkstra(0);
for (int i = 0 ; i < distance.length; ++i){
System.out.println(i + ":"+distance[i]);
}
}
}
```
注意⚠️:Dijkstra 算法并不适用于边的权值为负数的情况。
算法时间复杂度:O(|V|^2)。
\#\#\# 2. Floyd(各顶点之间最短路径)
Floyd 算法的思想很简单,只需要将图中所有的顶点轮流当一次中转节点即可,其算法的主要思想就是就对图进行 V 次的 Dijkstra 算法,其中 V 为图中节点个数。
其实现代码如下所示
```
// 以邻接矩阵表示法表示,并且是一个有向图
import java.util.Arrays;
// Graph 图
public class Graph {
// inf 定义最大值
private static final int INF = 10000007;
// vertices 节点个数
private int vertices;
// adjacencyMatrix 邻接矩阵
private int[][] edge;
public Graph(int v) {
vertices = v;
edge = new int[v][v];
// 初始化邻接矩阵
for(int i = 0; i < edge.length; ++i){
Arrays.fill(edge[i], INF);
}
}
// addEdge 初始化图的边
public void addEdge(int source, int destination, int weight) {
edge[source][destination] = weight;
}
public int[][] Floyd() {
// 初始化一个 distance 数组, 数组中的内容与 edge 数组相同
// distance 数组表示节点之间的最短距离
// distance[i][j] 表示节点 i 和节点 j 之间的最短距离为 distance[i][j]
int[][] distance = new int[vertices][vertices];
for (int i = 0; i < vertices; ++i) {
System.arraycopy(edge[i], 0, distance[i], 0, vertices);
}
// 节点 k 作为中转节点
for (int k = 0; k < vertices ; ++k){
// i 为起始节点
for (int i = 0; i < vertices ;++i){
// j 为终止节点
for (int j = 0 ; j < vertices; ++j){
// 如果起始节点和终止节点相同,则最短距离就是 0
if (i == j){
distance[i][j] = 0;
}else{
// 否则尝试是否可以使用中转节点 k 缩短两个节点之间的距离
distance[i][j] = Math.min(distance[i][j], distance[i][k] + distance[k][j]);
}
}
}
}
return distance;
}
}
public class Main {
public static void main(String[] args) {
int V = 5; // 图的顶点数
Graph graph = new Graph(V);
graph.addEdge(0, 1, 10);
graph.addEdge(0, 4, 5);
graph.addEdge(1, 2, 1);
graph.addEdge(1, 4, 2);
graph.addEdge(2, 3, 4);
graph.addEdge(3, 0, 4);
graph.addEdge(3, 2, 6);
graph.addEdge(4, 1, 3);
graph.addEdge(4, 2, 9);
graph.addEdge(4, 3, 2);
int[][] distance = graph.Floyd();
for (int i = 0 ; i < distance.length; ++i){
for (int j = 0; j < distance[i].length; j++){
System.out.printf("%d ",distance[i][j]);
}
System.out.println();
}
}
}
```
注意⚠️:Floyd 算法允许图中有带负权值的边,但不允许有包含带负权值的边组成的回路。。
算法时间复杂度:O(|V|^3)。
\#\# 拓扑排序
AOV网:若用 DAG 图表示一个工程,其顶点表示活动,用有向边<Vi,Vj>表示活动Vi以必须先于活动 Vj进行这样一种关系,记为 AOV 网。在AOV网中,活动Vi是活动Vj进的直接前驱,活动Vj是活动Vi的直接后继节点,这种前驱和后继关系具有传递性,且任何活动Vi不能以它自己作为自己的前驱或后继。
在图论中,拓扑排序通常用来判断一个有向图中是否存在环或者说是否存在循环依赖。由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,称为该图的一个拓扑排序:
- 每个顶点出现且只出现一次;
- 如果顶点 A 在序列中排在顶点 B 的前面,则在图中不存在从顶点 B 到顶点 A 的路径。
或定义为:拓扑排序是对有向无环图的顶点的一种排序,它使得若存在一条从顶点 A 到顶点 B 的路径,则在排序中顶点 B 出现在顶点 A 的后面。
拓扑排序算法流程如下:
1. 在有向图中选择一个没有前驱的节点,并输出(找到一个入度为 0 的顶点);
2. 从网中删除该顶点和所有以它为起点的有向边;
3. 重复 1 和 2 直到当前的图为空或当前网中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
算法过程图如下图所示
{:width=700}
通过上图的过程,可得到一个拓扑排序:0,1,3,2,4
具体算法代码实现如下:
```
// 有向图,并且使用邻接矩阵表示
import java.util.ArrayList;
import java.util.Stack;
// Graph 图
public class Graph {
// vertices 节点个数
private int vertices;
// adjacencyMatrix 邻接矩阵
private int[][] adjacencyMatrix;
// indegree 节点入度矩阵
private int[] indegree;
public Graph(int v) {
vertices = v;
adjacencyMatrix = new int[v][v];
indegree = new int[v];
}
// addEdge 初始化图的边
public void addEdge(int source, int destination) {
adjacencyMatrix[source][destination] = 1;
// 记录节点的入度
indegree[destination] += 1;
}
// TopologicalSort 拓扑排序
public void TopologicalSort(){
ArrayList<Integer> ans = new ArrayList<Integer>();
// stack 按照 dfs 方式进行拓扑排序
// 当然也可以使用队列方式按照 bfs 方式进行拓扑排序
Stack<Integer> stack = new Stack<>();
for(int i = 0; i < vertices; i++){
// 将所有入度为 0 的节点全部放入栈中
if (indegree[i] == 0){
stack.push(i);
}
}
// 当栈不空时,进行循环
while (!stack.isEmpty()){
// 获取当前栈顶元素,并放入到结果中
int curNode = stack.pop();
ans.add(curNode);
for (int i = 0; i < vertices; i++){
// 遍历邻接矩阵,如果存在和当前输出节点有一条有向边,则对其入度-1
// 如果入度变为 0 则需要放入到栈中
if (adjacencyMatrix[curNode][i] == 1){
indegree[i] -= 1;
if (indegree[i] == 0){
stack.push(i);
}
}
}
}
// 判断是不是所有节点都在结果中
// 如果不是则代表图中有环
if (ans.size() != vertices){
System.out.println("图中存在环,无拓扑排序");
return;
}
// 否则存在拓扑排序,将其输出
for(Integer item : ans){
System.out.println(item);
}
return;
}
}
public class Main {
public static void main(String[] args) {
int V = 5; // 图的顶点数
Graph graph = new Graph(V);
graph.addEdge(0, 1);
graph.addEdge(0, 3);
graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
graph.addEdge(3, 2);
graph.addEdge(3, 4);
graph.TopologicalSort();
}
}
```
注意⚠️:这里需要注意,拓扑排序通常不唯一,取决于选择入度节点为 0 的节点的顺序。若一个顶点有多个直接后继,则拓扑排序的结果通常不唯一;但若各个顶点已经排在一个线性有序的序列中,每不顶点有唯一的的驱后继关系,则拓扑排序的结果是唯一的。
时间复杂度:由于输出每个顶点的同时还要找打以它为起点的所有有向边,故采用邻接表存储时拓扑排序的时间复杂度为$$O(|V|+|E|)$$,采用邻接矩阵存储时拓扑排序的时问复杂度为$$O(|V|^2)$$。
\#\# 并查集
并查集(Union Find)是一种用于处理不相交集合的数据结构和算法,主要用于解决动态连通性问题。
并查集有两个基本概念:
1. 集合(Set):不相交的元素组,每个元素只属于一个集合。
2. 代表元素(Representative element):集合中的一个元素,用于标识整个集合。通常选择集合中的某个特定元素作为代表元素。
主要操作:
1. 查找(Find):确定一个元素所属的集合,即找到该元素所在集合的代表元素。
2. 合并(Union):将两个集合合并为一个集合。通常是将一个集合的代表元素指向另一个集合的代表元素。
并查集的算法流程如下:
1. 通常使用数组来实现并查集,数组的每个索引代表一个元素,数组的值表示该元素的父节点。如果一个元素的父节点是它自己,那么它就是该集合的代表元素。
2. 在查找操作中,通过不断地追溯一个元素的父节点,直到找到代表元素。为了提高查找效率,可以在查找过程中进行路径压缩,即将路径上的所有元素直接指向代表元素。
3. 在合并操作中,先找到两个元素所在集合的代表元素,然后将其中一个代表元素指向另一个代表元素。
以下是以图为例的并查集(Union Find)算法的 Java 实现及解释:
我们可以用一个数组来表示并查集的数据结构,其中数组的每个索引代表图中的一个顶点,数组的值表示该顶点的父节点。如果一个顶点的父节点是它自己,那么它就是该集合的代表元素。
```
class UnionFind {
private int[] parent;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
// 查找操作 - 递归实现
public int find(int x) {
if (x == parent[x]) {
return parent[x];
}
return find(parent[x]);
}
// 查找操作 - 迭代实现
public int find(int x) {
while (x != parent[x]) {
x = parent[x];
}
return parent[x];
}
// 合并操作
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootX] = rootY;
}
}
}
```
时间复杂度和空间复杂度
1. 时间复杂度:
- 查找操作(find)在进行路径压缩后,平均时间复杂度接近O(α(n)),其中 α(n) 为阿克曼函数的反函数,在实际应用中可以近似看作常数时间。
- 合并操作(union)的时间复杂度也接近常数时间。
2. 空间复杂度:并查集数据结构需要一个数组来存储每个顶点的父节点信息,空间复杂度为O(n),其中n是图中的顶点数量。
评论 (7)
