

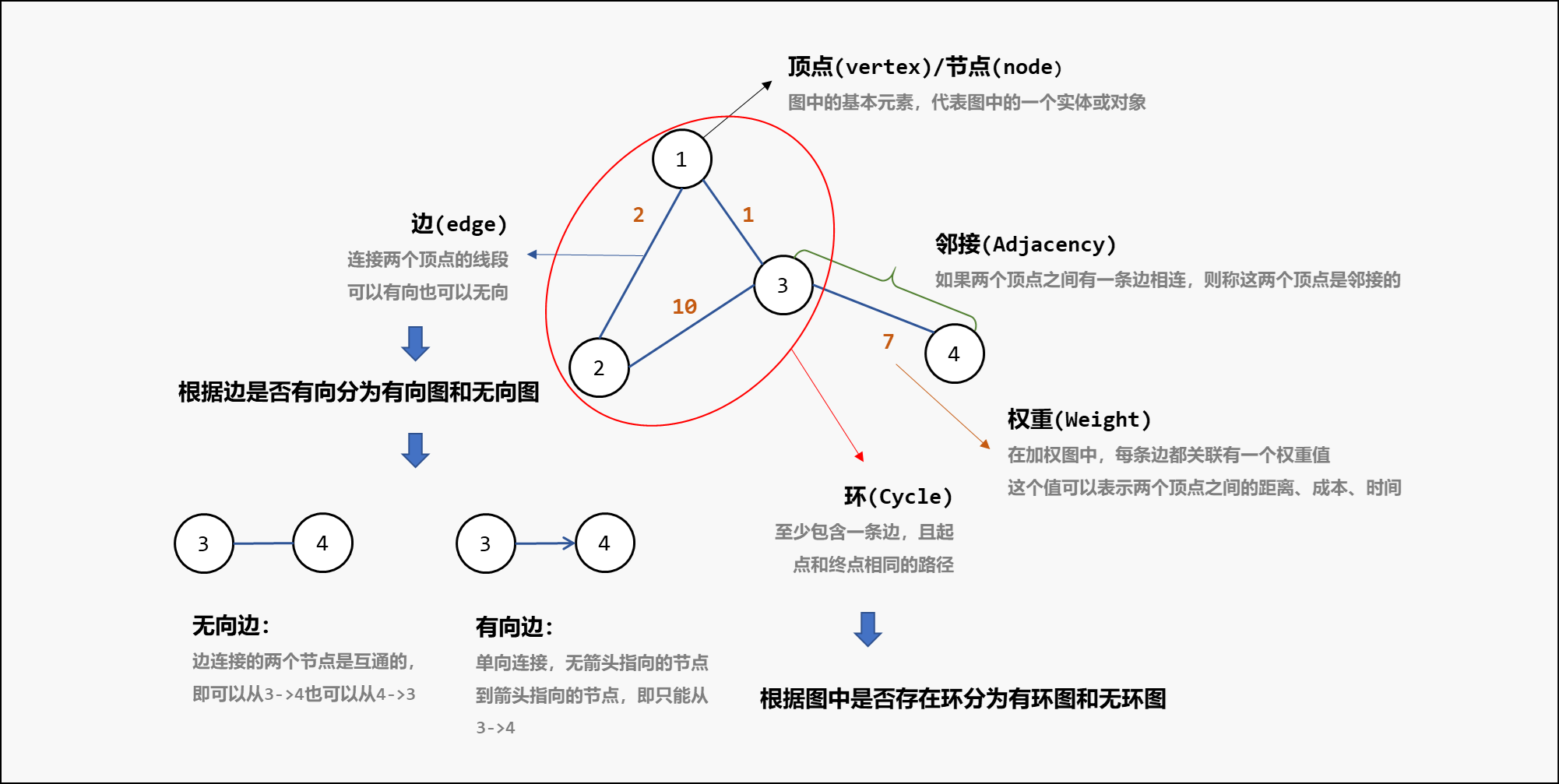
图的基本概念
深度优先搜索
引入 / 深度优先搜索过程
我们想要不重复不遗漏的遍历图上的每一个节点,应该怎么做呢!

我们可以看到整个搜索过程需要几个信息:
- 我们要知道每个节点的邻节点有哪些,才能进行转移;
- 我们要知道哪些节点被遍历过,才能不重复的遍历;
- 我们对于每个未遍历的节点的处理都是一样的,都是转移到 一个未遍历的邻节点,等所有邻节点都处理完了,再往回走。
因此我们可以概括主要步骤如下:
主要步骤
- 选择搜索起点:图搜索总要从某一个节点开始,我们才知道从哪一个节点开始走;
- 标记访问过的节点:将每一次访问到的节点标记为已访问,避免重复访问;
- 搜索相邻节点:接着为了探索更多节点,我们就要从当前节点出发去找继续找未访问过的邻节点;
- 回溯:我们每次都沿着当前节点的邻节点去走,直到没有未访问的邻节点可以走;我们就返回上一个节点,继续去找它未访问过的邻节点;
- 重复过程:重复上述过程直到所有节点都访问了【或者说到达终点】
代码示例
图结构通常会以一个列表的形式给出,如 edges。列表中每个元素存放一组节点的连接关系,即 edge[i] = [node1, node2](如果是有权图,则有权重信息;如果是有向图的话,一般是 node1 -> node2,这里我们先以无向图为例)
我们通常需要将这个“边信息”列表转成一个“节点信息”列表 graph,graph[i]也是一个列表,存储节点 i 的所有邻节点。
函数参数:
edges:图中的所有边信息,形式如[node1, node2];如果是带权重的,则形式如[node1, node2, weight]start:搜索起点;n:节点总数;
无向无权图
输出每个遍历到的节点的编号
class Solution {
public void dfs(int[][] edges, int start, int n){
List<Integer>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1];
neighbors[node1].add(node2); // 边的两个端点互为彼此的邻节点
neighbors[node2].add(node1);
}
dfs(start, neighbors, visited); // 从start节点开始进行深度优先搜索
}
private void dfs(int node, List<Integer>[] neighbors, boolean[] visited){
System.out.print(node + " "); // 当前步骤的操作,可替换,这里输出这个节点的值
visited[node] = true; // 标记节点node已经搜索,避免重复
for(int nei: neighbors[node]){ // 根据邻接表,枚举节点node的所有邻节点
if(!visited[nei]){
dfs(nei, neighbors, visited); // 如果邻节点nei未访问过,递归访问
}
}
}
}有向有权图
输出每个遍历到的节点的编号和对应边的权重
class Solution {
private void dfs(int node, List<int[]>[] neighbors, boolean[] visited){
visited[node] = true; // 标记节点node已经搜索,避免重复
for(int[] nei: neighbors[node]){ // 根据邻接表,枚举节点node的所有邻节点
if(!visited[nei[0]]){
System.out.println(nei[0] + " " + nei[1]); // 当前步骤的操作,可替换,这里输出这个节点的值
dfs(nei[0], neighbors, visited); // 如果邻节点nei未访问过,递归访问
}
}
}
public void dfs(int[][] edges, int start, int n){
List<int[]>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点和对应权重
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点已访问
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1], weight = e[2];
neighbors[node1].add(new int[]{node2, weight}); // 边的两个端点互为彼此的邻节点
}
dfs(start, neighbors, visited); // 从start节点开始进行深度优先搜索
}
}树形图的深度优先搜索
树形图就是形状和树结构一样的图,即 n 个节点只有 n - 1 边,保证每个节点 至少 一条边和其他节点相连。

class Solution {
public void dfs(int[][] edges, int start, int n){
List<Integer>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1];
neighbors[node1].add(node2); // 边的两个端点互为彼此的邻节点
neighbors[node2].add(node1);
}
dfs(start, neighbors, -1); // 从start节点开始进行深度优先搜索,根节点没有父节点,用-1表示
}
private void dfs(int node, List<Integer>[] neighbors, int pa){
System.out.print(node + " "); // 当前步骤的操作,可替换,这里输出这个节点的值
for(int nei: neighbors[node]){ // 根据邻接表,枚举节点node的所有邻节点
if(nei != pa){
dfs(nei, neighbors, node); // nei是node的子节点,递归访问
}
}
}
}概述
深度优先搜索(DFS, Depth-First Search)算法是一种用于遍历或搜索树或图的算法。
它的基本思想是尽可能深地搜索图的分支,直到达到叶子节点(即没有未访问的相邻节点的节点)或达到目标节点,然后回溯到上一个节点,继续探索其他未探索的分支,直到整个图都被探索完毕。
你可以理解成 DFS 它是一个愣头青,它 沿着一条路走到底 ,不撞南墙不回头。
应用场景
- 二叉树的三种遍历:前序 / 中序 / 后序 遍历本质上也是一种深度优先搜索,只是说二叉树有向无环,因此一定不会存在重复。
广度优先搜索
引入 / 广度优先搜索过程
我们想要不重复不遗漏的遍历图上的每一个节点,应该怎么做呢!

我们可以看到整个搜索过程需要几个信息:
- 我们要知道每个节点的邻节点有哪些,并且要记录这些邻节点,才能把一次性把邻节点都遍历了;
- 我们要知道哪些节点被遍历过,才能不重复的遍历;
- 我们对于每个未遍历的节点的处理都是一样的,都是转移到 一个未遍历的邻节点,等所有邻节点都处理完了,再处理下一个节点。
因此我们可以概括主要步骤如下:
主要步骤
- 选择一个源节点:首先,你需要从图中选择一个节点作为搜索的起点。
- 初始化队列:将源节点放入队列中。
- 访问节点:当队列非空时,执行以下步骤:
- 从队列中移除一个节点(队首节点)。
- 访问该节点(例如,打印节点值,或进行其他处理)。
- 将该节点的所有未访问过的邻接节点加入队列。
- 重复直到队列为空:重复上述步骤,直到队列为空,此时表示所有从源节点可达的节点都已被访问。

(**注意:**我们在将邻节点加入队列的同时就要将邻节点标记为已访问过,而不是等到处理到邻节点再标记;这样才不会导致邻节点重复加入队列:
比如访问到节点0的时候,将节点1和节点2都加入队列;如果此时不将节点2标记已访问,那么下一步访问到节点0时,节点2也是节点1的邻节点且未访问,就会重复加入队列;)
代码示例
图结构通常会以一个列表的形式给出,如 edges。列表中每个元素存放一组节点的连接关系,即 edge[i] = [node1, node2](如果是有权图,则有权重信息;如果是有向图的话,一般是 node1 -> node2,这里我们先以无向图为例)
我们通常需要将这个“边信息”列表转成一个“节点信息”列表 graph,graph[i]也是一个列表,存储节点 i 的所有邻节点。
函数参数:
edges:图中的所有边信息,形式如[node1, node2];如果是带权重的,则形式如[node1, node2, weight]start:搜索起点;n:节点总数;
无向无权图
输出每个遍历到的节点的编号
class Solution {
public void bfs(int[][] edges, int start, int n){
List<Integer>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1];
neighbors[node1].add(node2); // 边的两个端点互为彼此的邻节点
neighbors[node2].add(node1);
}
Queue<Integer> qu = new LinkedList<>(); // 初始化队列
qu.offer(start); // 将起点入队
visited[start] = true; // 起点入队即标记已访问
while(!qu.isEmpty()){
int node = qu.poll(); // 获取并弹出队首节点
System.out.print(node + " "); // 执行的操作
for(int nei: neighbors[node]){ // 获取当前节点的所有邻节点
if(!visited[nei]){
qu.offer(nei); // 将未访问的邻节点加入队列
visited[nei] = true; // 入队即为已访问
}
}
}
}
}有向有权图
输出每个遍历到的节点的编号和对应边的权重
class Solution {
public void bfs(int[][] edges, int start, int n){
List<int[]>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点和对应权重
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点已访问
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1], weight = e[2];
neighbors[node1].add(new int[]{node2, weight}); // 边的两个端点互为彼此的邻节点
}
Queue<int[]> qu = new LinkedList<>(); // 初始化队列
qu.offer(new int[]{start, 0}); // 将起点入队
visited[start] = true; // 起点入队即标记已访问
while(!qu.isEmpty()){
int[] node = qu.poll(); // 获取并弹出队首节点
System.out.println(node[0] + " " + node[1]); // 执行的操作
for(int[] nei: neighbors[node[0]]){ // 获取当前节点的所有邻节点
if(!visited[nei[0]]){
qu.offer(nei); // 将未访问的邻节点加入队列
visited[nei[0]] = true; // 入队即为已访问
}
}
}
}
}概述
图的广度优先搜索(Breadth-First Search, BFS)是一种用于遍历或搜索树或图的算法。
它的基本思想是尽可能广地每个节点相邻范围;即从一个选定的源节点开始,探索所有邻近的节点,然后再从这些节点开始,继续探索它们的邻近节点,以此类推,直到访问了图中所有可达的节点。
BFS 使用队列(Queue)来实现这一过程,队列是一种先进先出(FIFO)的数据结构。
应用场景
- 无向图的最短路径
连通块

概述
连通块只是图论中的一个概念,并没有什么新的算法。只是这个概念比较常用,因此单独列出来说明一下。主要是为了说明如何统计图中连通块个数
连通块是指图中由相互连接的顶点组成的子集,换句话说,连通块内部的所有顶点彼此之间都是连通可达的;
- 如果一个图只有一个连通块,则称之为连通图;
- 如果一个图有多个连通块,则称之为非连通图;
代码示例
连通块的使用场景通常是统计图上的连通块个数。而统计连通块个数方法实际就是图搜索:我们需要去搜索每个节点所在的连通块。

代码还有一个前提是 n 个节点的编号为 [0, n-1]才能用列表存储邻接表和访问表,否则用哈希表。
class Solution{
public int countConnectBlocks(int[][] edges, int n){
List<Integer>[] neighbors = new ArrayList[n]; // 邻接表,neighbors[i]存储节点i的所有邻节点
for(int i = 0; i < n; i++){
neighbors[i] = new ArrayList<>(); // 初始化每个节点的邻接表neighbors[i]
}
boolean[] visited = new boolean[n]; // 访问表,visited[i]为true表示节点
for(int[] e: edges){ // 枚举每一条边edge的信息
int node1 = e[0], node2 = e[1];
neighbors[node1].add(node2); // 边的两个端点互为彼此的邻节点
neighbors[node2].add(node1);
}
int block = 0; // 统计连通块个数
for(int i = 0; i < n; i++){ // 枚举每个节点i作为起点进行深度优先搜索
if(visited[i])continue; // 已处理过的节点说明是在之前的某个连通块上,不重复处理
dfs(i, neighbors, visited); // 未处理的节点一定在一个新的连通块上,以其为起点搜索其所在的连通块
block++; // 累加一个连通块
}
return block;
}
private void dfs(int node, List<Integer>[] neighbors, boolean[] visited){
visited[node] = true; // 标记节点node已经搜索,避免重复
for(int nei: neighbors[node]){ // 根据邻接表,枚举节点node的所有邻节点
if(!visited[nei]){
dfs(nei, neighbors, visited); // 如果邻节点nei未访问过,递归访问
}
}
}
}