
#遍历问题
##前序遍历
定义是先访问根节点,再访问左孩子节点,再访问右孩子节点
###递归算法
先上代码
class Solution {
public:
void preorder(TreeNode *root, vector<int> &res) {
if (root == nullptr) {
return;
}
res.push_back(root->val);
preorder(root->left, res);
preorder(root->right, res);
}
vector<int> preorderTraversal(TreeNode *root) {
vector<int> res;
preorder(root, res);
return res;
}
};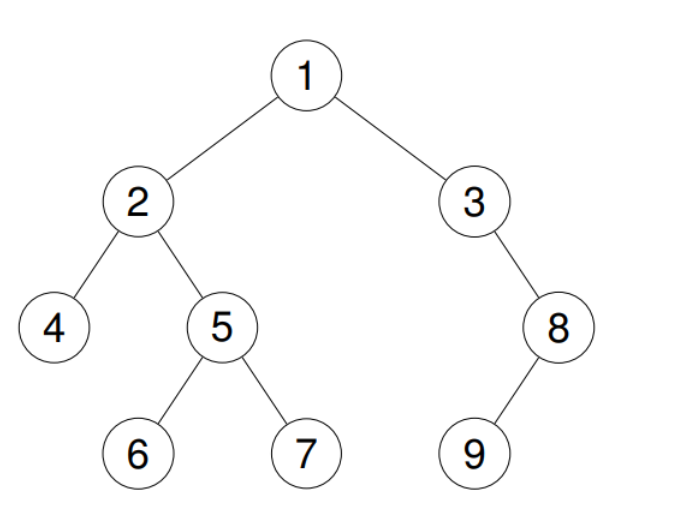
我的理解是一上来先访问根节点,把根节点的值添加到res中,再把根节点的左孩子节点当做此时的根节点依次类推。如上图,依次把1,2当做根节点,再把4当做根节点,再把4的左孩子当根节点,此时的根节点为空,所以返回到上一级,也就是4当根节点的那一级,既然4的左孩子已经访问完,那就**preorder(root->right, res);那就执行这一行代码
发现和左孩子一样,又被跳回到4这一级,这是4这一级函数已经执行完了,其实啊,4这一级是2的preorder(root->left, res);这一行代码,4已经结束了,当然跳回到2的这里,那么该执行2的preorder(root->right, res);**这一行代码,开始把5当做头结点,就和4类似。
下面还有递归方法,就不再赘述了
重点来了,非递归算法
简单来说就是用到了栈来替代递归,先上代码
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int>ans;
if(root==nullptr)
{
return ans;
}
TreeNode* cur=root;
stack<TreeNode*>stk;
while(cur!=nullptr||!stk.empty())
{
while(cur!=nullptr)
{
ans.push_back(cur->val);
stk.push(cur);
cur=cur->left;
}
cur=stk.top();
stk.pop();
cur=cur->right;
}
return ans;
}
};
我的理解
还是这个图,简单解释一下。
cur现在是指向root节点,第一个while条件稍后做解释,先看第二个while条件是cur不是空时,那就进入这个循环,访问1,然后把1压入栈中,指向cur的左孩子,然后继续这个循环,(注意,这里一直在里面的那个循环,还没出来呢)把2压入栈中,指向2的左孩子,把4压入栈中,指向4的左孩子,此时cur为空,里边的循环终于结束了,此时的栈为
| 栈顶 | 4 | 2 | 1 | 栈底 |
|---|---|---|---|---|
| 把上面那个表格想象成左边开口,右边封闭的样子。注意,存入栈中的事指针,是那个节点的位置,你可以将表格里的数字看成一个个节点,因为压入栈的不同的cur | ||||
| 一出里边的循环,先让cur指向4那个位置,再把栈顶元素弹出,最后让cur指向他的右孩子,也就是cur指向了4的右孩子,也就是空。现在一遍大的循环结束看看现在的栈 |
| 栈顶 | 2 | 1 | 栈底 |
|---|---|---|---|
| cur为空 | |||
| 依然满足循环条件,进入循环,此时不满足里边的循环了,所以cur指向2的位置,栈再把2弹出,cur指向2的右孩子结束了这次循环依次类推。 |
关于第一个while循环条件为什么那样呢,做个解释
因为在进入循环后,当cur不为空时,都会把他压栈就像做个标记,里边的while循环一直顺着左孩子访问下来,访问到空为止,一旦左边空了,跳出里边while循环,找到栈顶,再把栈顶弹出,也就是最后压进栈的元素,访问他的右孩子,如果他没有右孩子那就再看看栈顶的元素有没有右孩子,依次类推,直到栈为空了,cur也为空了,就说明全部遍历结束。
其实就是左孩子一直找到头,遇到一个节点就压到栈里做标记,因为每个节点都有可能是个分支,也就是岔路口,你倒着回来看看一个个岔路口。
##中序遍历
这个和前序差不多,直接上代码
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*>stk;
vector<int>ans;
TreeNode* t;
t=root;
while(t!=nullptr||!stk.empty())
{
while(t)
{
stk.push(t);
//如果是前序,访问函数在这
t=t->left;
}
t=stk.top();
stk.pop();
ans.push_back(t->val);//访问函数在这
t=t->right;
}
return ans;
}
};其实就是访问时机变了
除了上面介绍的前序和中序,还有后序和层序。
由于今天不是周末,没那么多时间,所以剩余部分放在这周末。因为我也是学生,正在上数据结构这门课,所以就想以这样的方式做笔记,而且我的很多措辞没有那么专业,解释也没有课本那么详细,但是这是我的理解,我认为我能把它讲清楚也就能更深的理解。
除此之外要是能帮我到一些和我一样的小白,那也是非常值得的。我对于刷题深有体会,刚开始做题看到评论区和题解里边各种术语,比如“深度搜索”“dfs”“双指针”“动态规划”等等都是一头雾水,完全看不懂,感觉是很难的知识(实际也很难),就很容易放弃,我想说的是别怕,坚持一下就好了,可以看看灵茶山艾府的题单,把各种难题分类,从易到难,就很容易坚持下去,甚至会喜欢上刷题,一起加油吧。
如果以上内容有问题或解释错误的地方,也希望提出来,共同改进。
谢谢你的观看。
